I would like to try using dwidenoise, however I am not 100% sure of its optimal use. I have multi-shell data (b=0, b=1000, b=2500). Should I provide all dwi volumes (including b=0 and both nonzero shells) in one file to dwidenoise or is it better for optimal performance to split data to separate shells and process them separately?
Processing all the data seems to be recommended use in the tutorial.
On the other hand, the separate processing of each shell may indicate the Veraart’s paper where they show the results of each shell separately and it maybe makes more sense to me since the noise in the particular shells is typically different.
As is indeed recommended in the tutorial, we advise applying MP-PCA denoising to all data combined. Jelle Veraart supports this recommendation in his papers.
But you ask a valid question, and I’ll do my best to explain why there’s no reason to separate individual shells. It essentially boils down to your last sentence:
This is a common misconception. The noise level is constant across b-values (for fixed TE). The confusion arises because the signal attenuates so dramatically at high b-values that the signal-to-noise ratio (SNR) clearly drops. SNR is not to be confused with the noise level.
MP-PCA denoising assumes constant noise level. As I explained above, this assumption is not violated across b-values. Therefore you can safely use all DWI volumes combined, and the larger number will help to identify the data redundancy required for denoising. By operating in local patches, the algorithm also accounts for spatial variation in the noise level.
I hope that clarifies this topic. If not, just ask.
thank you for the clarification. As I am thinking on this further, I would like to ask several more questions:
Could you please additionally comment on if there are situations the dwidenoise use is not advisable?
I am especially in doubts in case of FSL BEDPOSTX, where denoising could possibly affect the estimation of “true” uncertainty of model estimates. What do you think?
I have some older data with 30 directions, 2 repetitions (i.e. 62 volumes). I am preparing the preprocessing for estimation of diffusion tensor parameters (for subsequent TBSS). Would you recommend to run denoising for these data? Is 62 volumes enough? Would you alter window size of such data? What is minimal number of volumes where dwidenoise would reasonably work?
The N>M rule recommended in tutorial http://mrtrix.readthedocs.io/en/latest/tutorials/denoising.html seems counter-intuitive to me, since it means that for smaller number of volumes I could use smaller window. I would expect opposite, i.e. only with higher number of volumes I can afford to lower the size of window to better grab spatial variance of noise.
We recommend to always inspect the residuals after denoising, as explained in the user guide. As long as the residuals don’t contain any structure, I can’t think of any situation in which MP-PCA denoising would bias certain estimates. If effective, denoising may reduce uncertainty on those estimates, but only to the extent that they would be influenced by acquisition noise. I would argue that’s a good thing.
As I said above, if the residuals don’t contain structure then you’re fine. The paper shows results for data with 60 DWI volumes, so that should be sufficient. I expect the default window size of 5x5x5=125 to be a good trade-off too.
Jelle Veraart may be in a better position to comment on this guideline, but I’ll do my best to provide some intuition. MP-PCA is fitting the Marchenko-Pastur distribution to the eigenvalue spectrum of the (patch-based) covariance matrix in each voxel, and uses this fit to select the optimal cut-off in the spectrum. The precision of this cut-off will depend on the “level of detail” in the spectrum histogram, determined by the dimensions of the covariance matrix, equal to the minimum of the no. DWI volumes (M) and the patch size (N). Therefore, you would ideally want both to be as large as possible. In practice, M is fixed and thus sets an upper bound on the rank for your data. If you choose N < M, you further reduce the “level of detail” in the spectrum. On the other hand, if N is too large you can violate the assumed noise homoscedasticity within the patch. Therefore, keep an eye on the residuals when you try different settings.
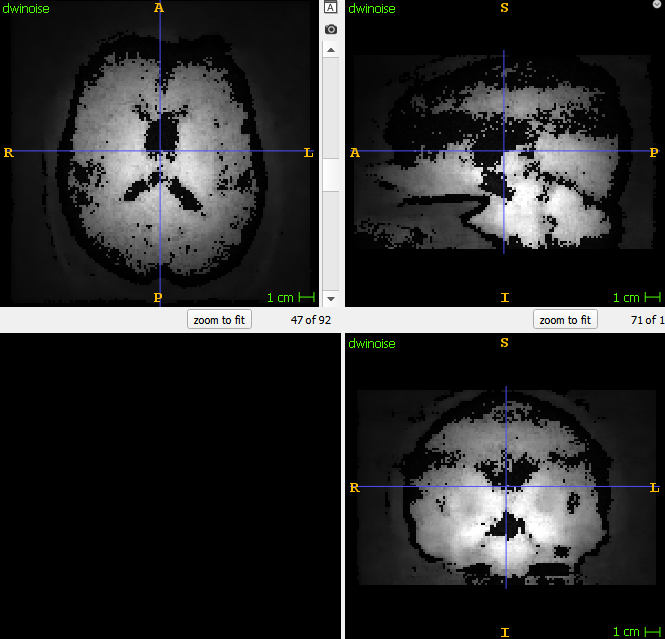
Hi all, I am using this old thread because it seems very similar to my question. I just applied dwidenoise on a multishell dataset. However, the DWI residuals output with the -noise look like it has some structure, and the brain emerges quite clearly. Here is a screenshot. I can upload the nifti somehwere if necessary (it doesn’t get uploaded here).
First of all an important distinction: the output -noise produces the noise level, which is not the same as the residuals. See the user guide for details on how to calculate those.
That said, your noise map certainly doesn’t look as expected. Can you check if the image value in the black voxels are NaN (not a number)? That would be a numerical issue I have seen before in fMRI data, but not yet in DWI data. Can you also try if a larger window size, e.g., -extent 7,7,7 or -extent 9,9,9, does produce a homogeneous noise map?
As a way forward, I have been working on improving numerical stability in the GitHub branch denoising_updates. Can you check if this works for you?
cd [your mrtrix folder]
git fetch
git checkout denoising_updates
./build
dwidenoise ... (as you did before)
If that still doesn’t help, try adding option -datatype float64 to test in double precision. Afterwards, you can reset your default mrtrix install with git checkout master && ./build.
@dchristiaens thank you for the advice, and sorry for the delay. I had to try on my local computer instead of the cluster, where I can’t install MRtrix without root access.
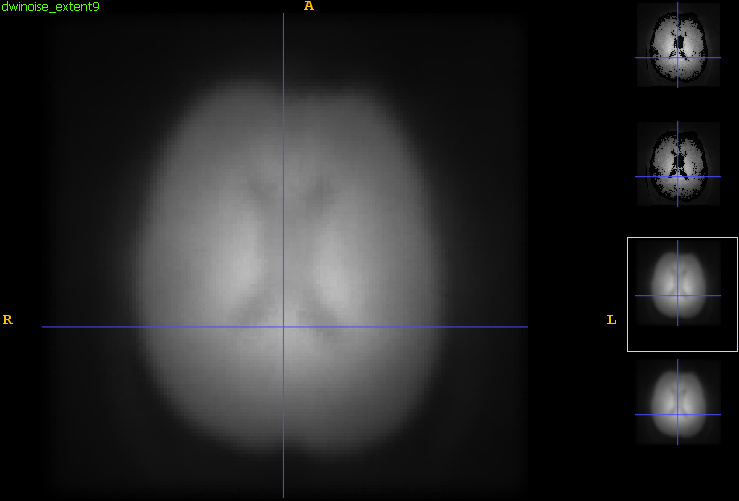
Here are the news. I tried both your updated branch and -extent 9,9,9. The updated branch did not make much difference. The increase in extent had some effect, mostly blurring the outcome, but I can still see brain features:
Apologies for my late reply. ISMRM got in the way…
Thank you for trying the increased patch size and the updated branch. It’s interesting to see the results, although I was expecting the updates to have at least some effect. If would certainly be helpful if you could send me your dataset please? I would like to have a better look into this.
In any case, while the ventricles should technically not stand out, their effect in your noise map with large patch size is fairly subtle. I expect that with 9x9x9 patches the data redundancy in this region decreases, yielding reduced noise level estimates. Ultimately, underestimating the noise level is harmless as this will result in less denoising in the ventricles, leaving your data closer to the original input. Have you tried 7x7x7 too? Most important is to check that the residuals on the denoised data do not contain structure. To this end, do:
where out.mif is the denoised DWI image. Ideally, these residuals are Gaussian distributed with zero-mean and contain no anatomical structure. See the user guide for more details.