I’m trying to run average_response on a number of white matter response functions text files. Here is my command: average_response /DIR/wm_avg/*.txt /DIR/wm_group.txt -force -debug
When I run it though I get the error message: Error in file /DIR/wm_group.txt: Input files do not contain
the same number of b-values
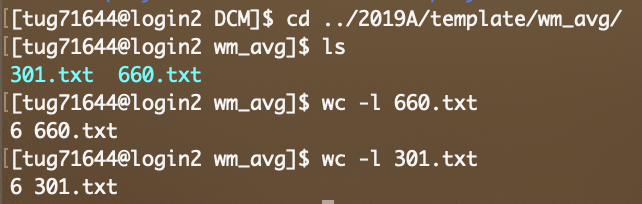
Initially I was trying it with 13 subjects to pilot the pipeline but upon running into this error I reduced it to two to see if that would help but I’m still getting the same error. As a reference, here is the content of the wm_rf.txt files
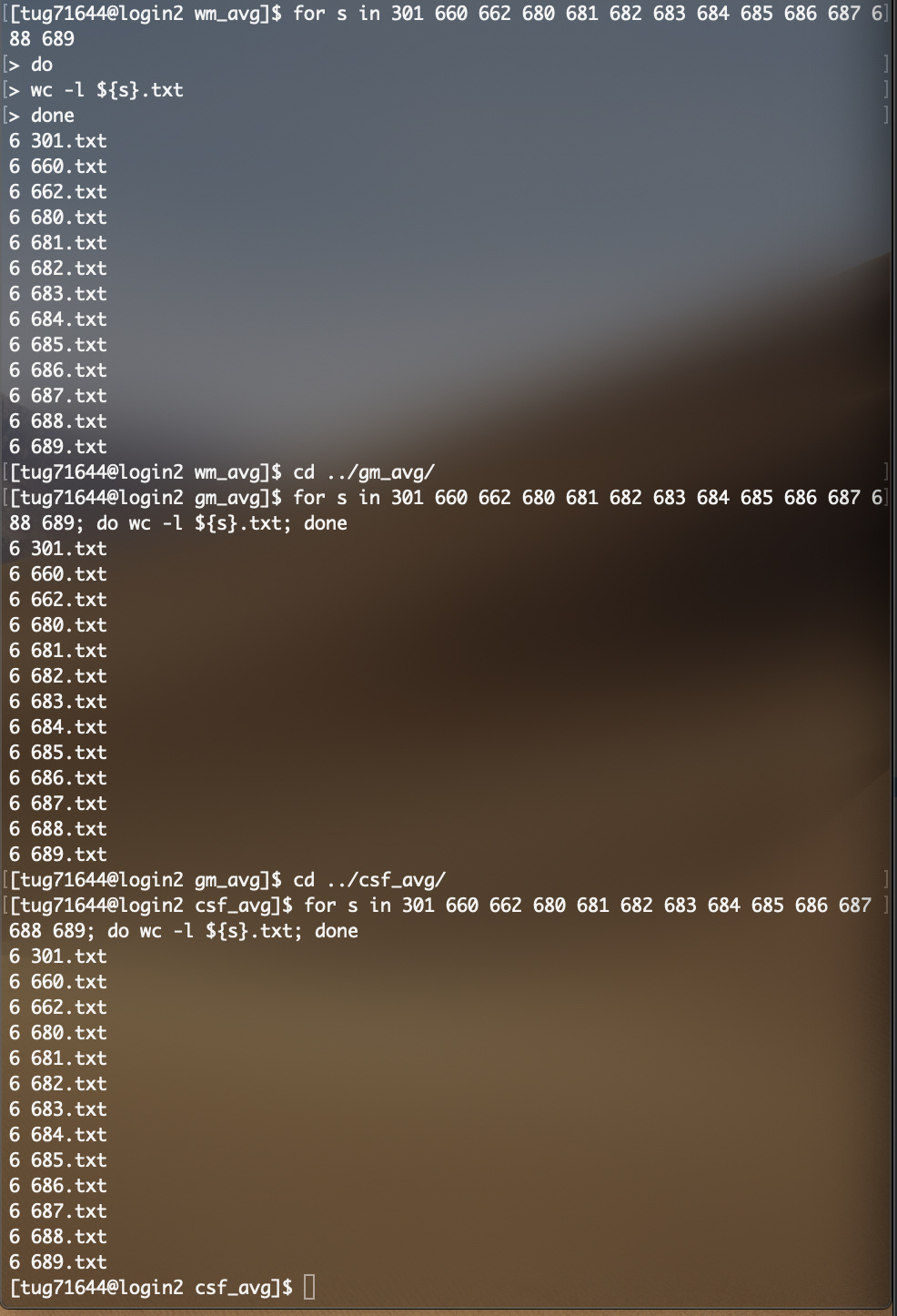
average_response is implemented as a python script, and looking at the current code, it looks like the number of shells is determined simply by the number of lines in the file, with no attempt to ignore empty lines. All it would take for that test to fail is an additional empty line at the end of the file. You can use wc -l 660.txt to check the number of lines in each response file. If they don’t match (which I assume is the issue), open the one with too many lines in a text editor, remove any superfluous empty lines, save and try again. Hopefully that’ll fix it…
The script itself is relatively simple, so it would not be too difficult to go in and see how the script itself is reading the data (as opposed to how some other unix command reads / displays the contents). E.g. After line 19:
lines = f.readlines()
, you could insert:
print (len(lines))
print (lines)
; that would tell you how many lines the script thinks that each file contains, and the contents of those lines. Seeing where the discrepancy is between how data from the two files is read would likely give a strong hint as to where the discrepancy is in the underlying data.
It wouldn’t surprise me if one of the files contains an empty line at the end whereas the other doesn’t, or one of the files doesn’t have a newline character at the end of the last data line whereas the other does, and this difference is being obscured currently because the wc command is based on different code and is accounting for such discrepancy intelligently whereas average_response is not.
When I added the line print(len(lines)) it spits out the below message. First of all, I’m feeding it 13 subjects so I’m not sure where its getting the idea that there are 15 subjects. Secondly, it spits out 14 different lines, the last of which is 0, which leads me to believe that the problem is that the last “phantom” subject the command is trying to deal with is the problem. How do I remedy this when the error is not caused by one of the .txt files I feed it but rather by some mysterious phantom which I cannot identify?
OK, it could be that you have hidden files in that folder? What does ls -a /DIR/wm_avg/ report? Alternatively, what’s the output if you put the word echo at the very beginning of your command?