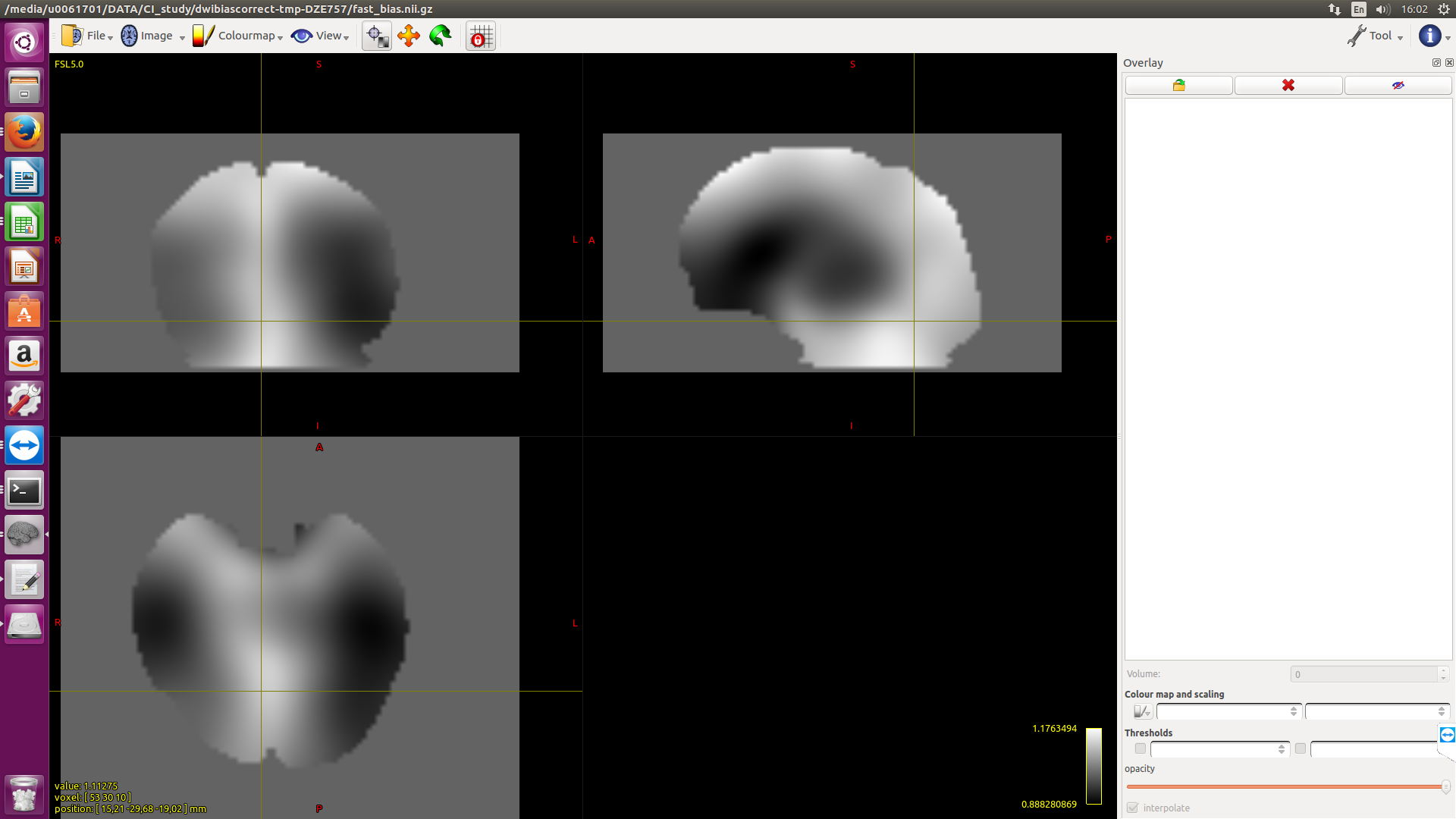
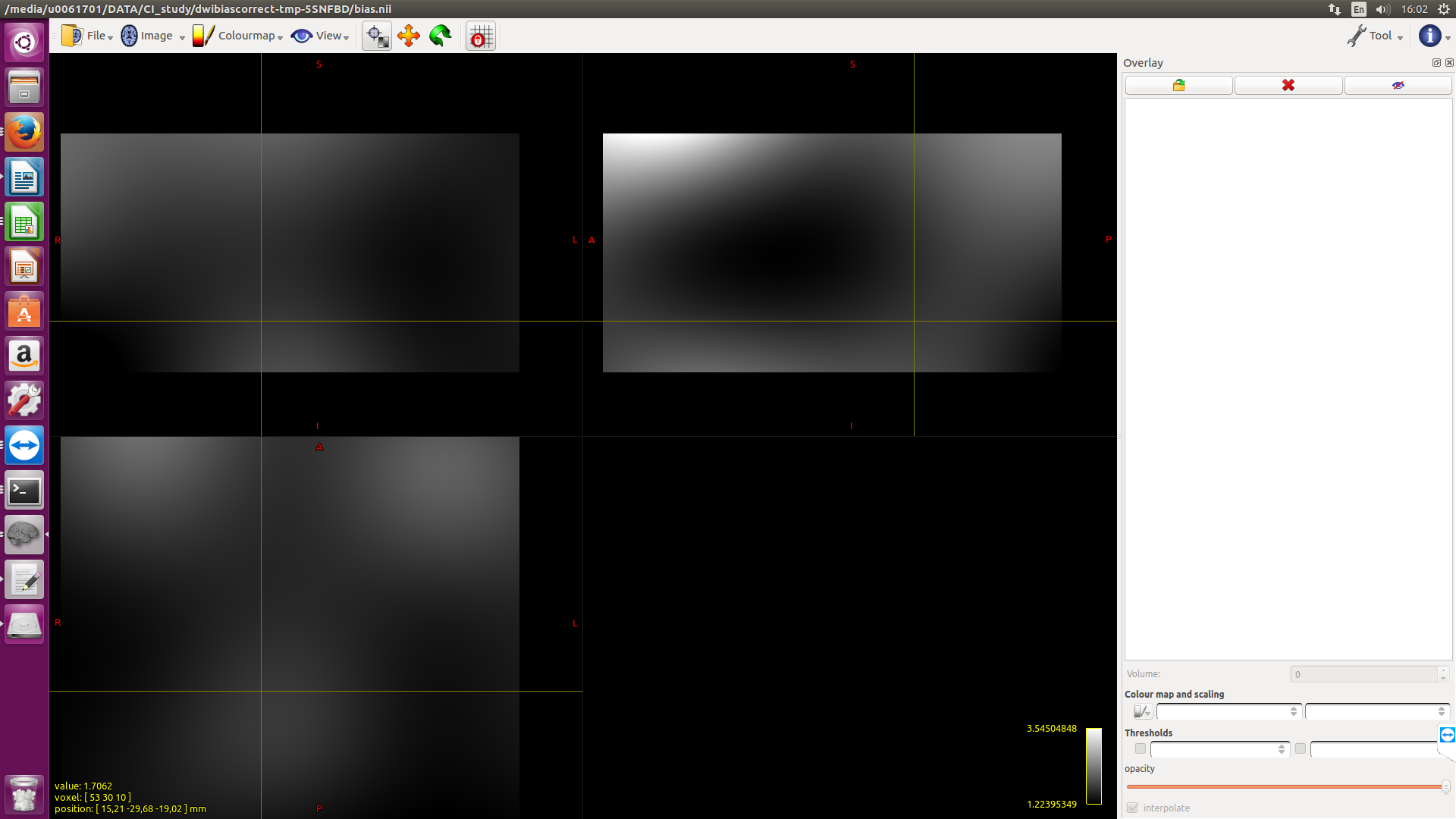
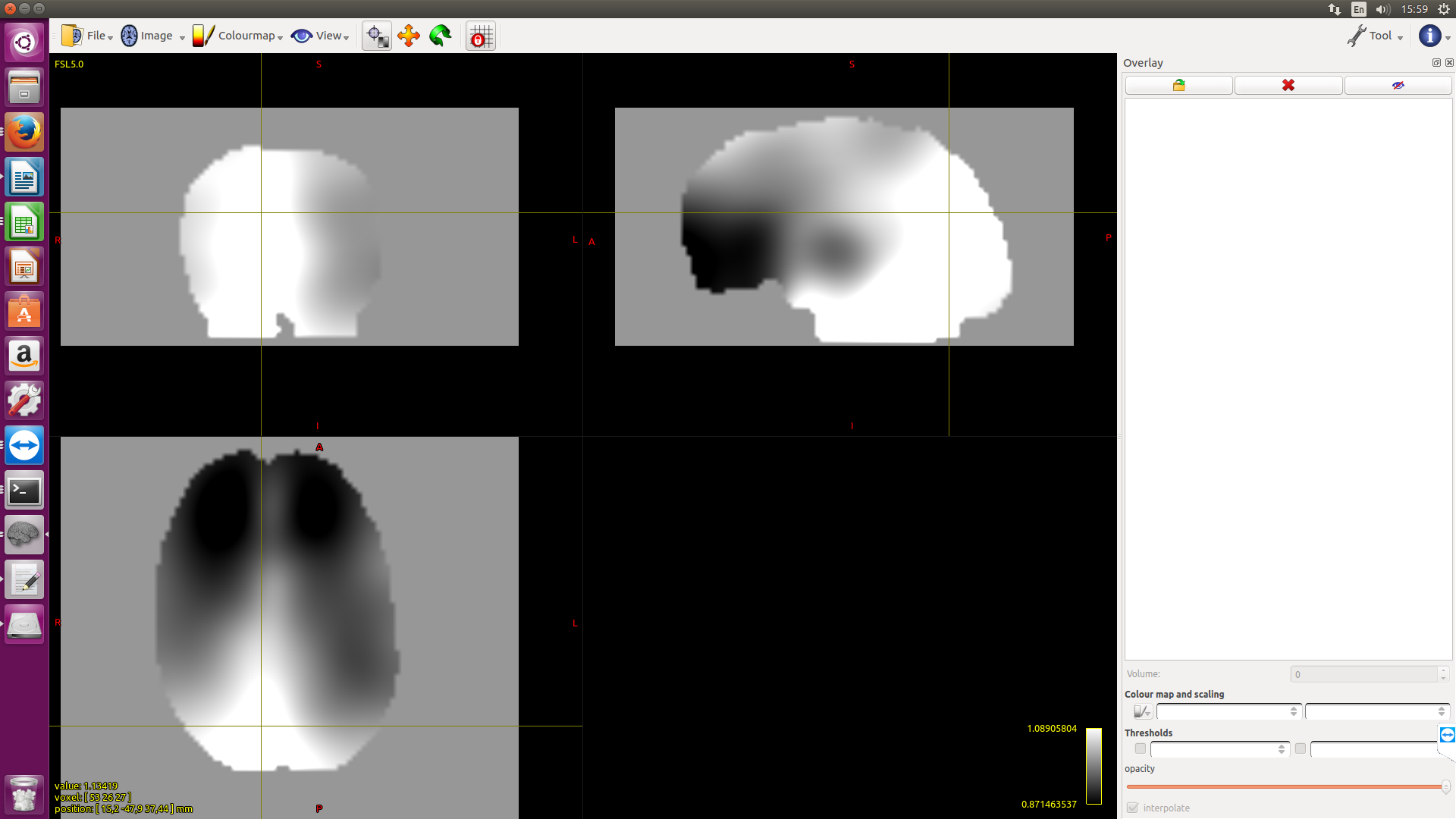
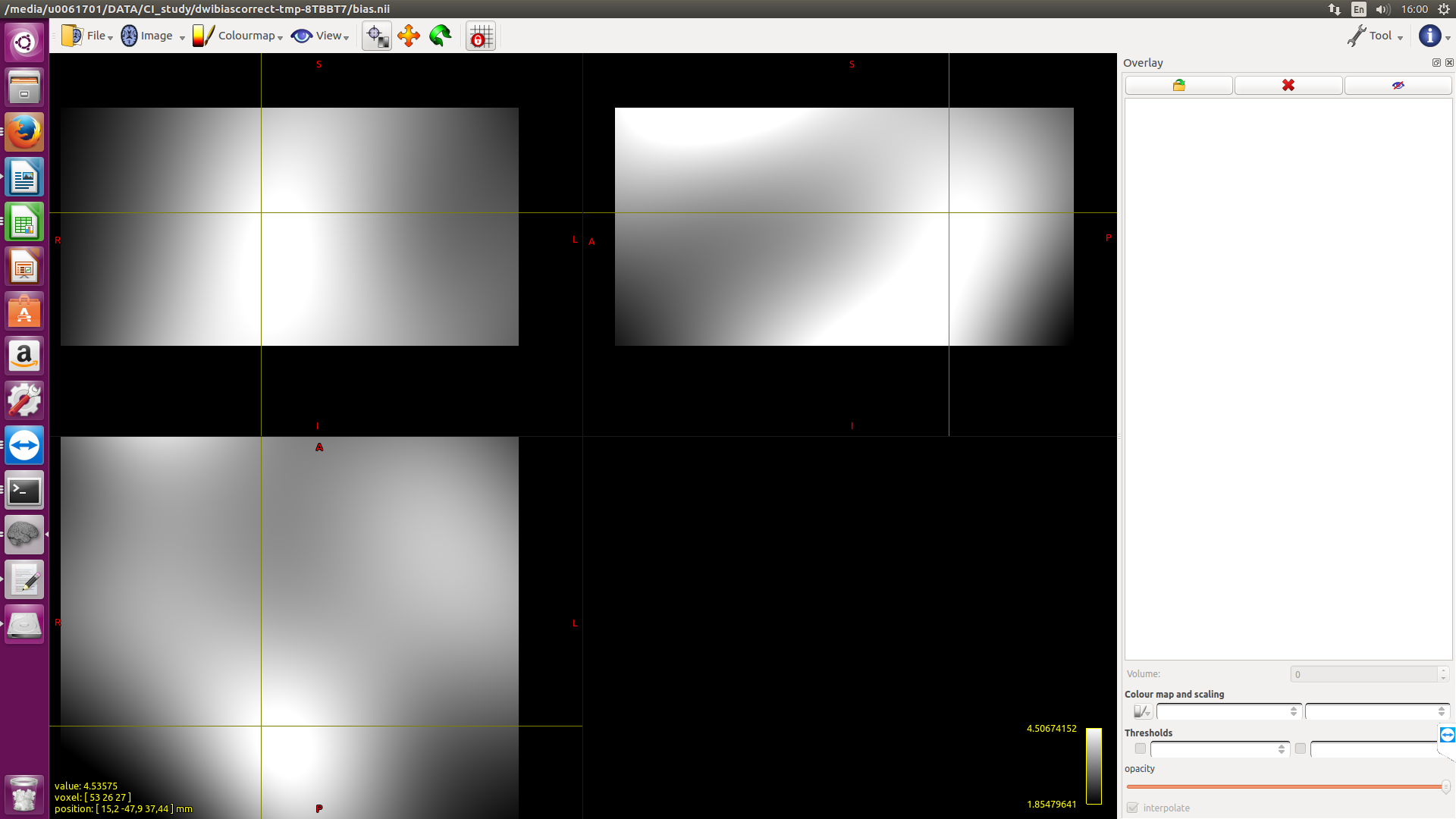
Probably the recommendation for bias field correction is ants but would someone expect to see a huge difference with fsl?
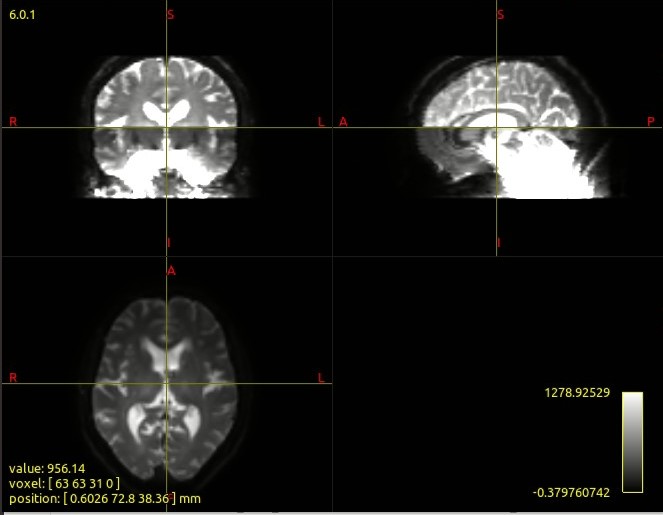
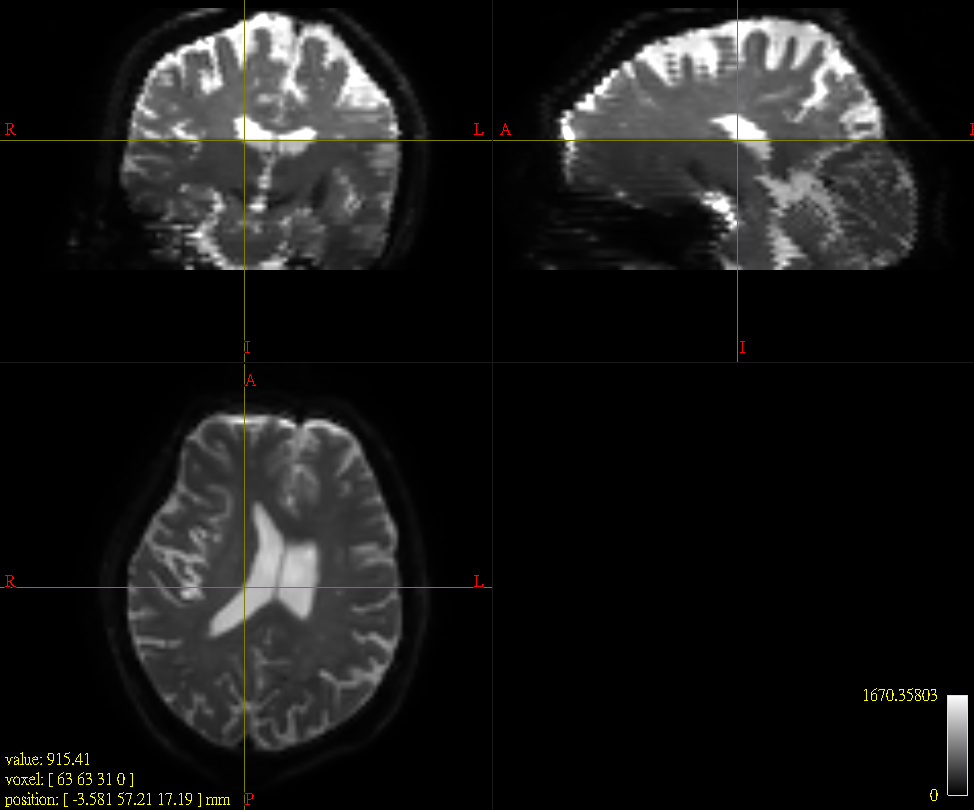
Here I applied both methods to 2 subjects. The outcomes for S2 are quiet different if one just looks at the value of the cursor position. Are the absolute values important?
The absolute values are definitely going to be important, since the magnitude of FD is directly modulated by this field. However in study data such as this, there is no objective marker by which to assess which bias field correction algorithm is “better”; this would need to be done with simulated data and a ground truth bias field, and I wasn’t able to find anything in the literature where this had been performed. So I can only recommend your own subjective assessment…
One can only hope that each method is itself consistent, even if the results are inconsistent between them, such that using the same method across a cohort does not introduce unwanted variance.
Hi dear experts,
I’m running the FD & FC single tissue CSD step by step according to the tutorial.
I’m also curious about why the tutorial suggesting against use of the -fsl option (4. Bias field correction).
1 of my 50 subjects somehow yielded weird output with the -ants option, which was otherwise okay with -fsl.
The principal reason for advising against use of the FSL bias field correction algorithm is that it fails to extrapolate the estimated bias field beyond the provided mask. This is conflated by the fact that estimated brain masks are often not very good prior to bias field estimation. So e.g. if a voxel at the edge of the brain is erroneously omitted from the mask, and the estimated bias field in an adjacent voxels that is included in the mask is say 30%, then following bias field correction there will be a 30% difference in image intensity between those two adjacent voxels. This would clearly be artefactual, and could have downstream effects e.g. in registration & transformation of FOD data to template space. I should perhaps at some point generate an example image with which I can demonstrate this behaviour.
If you have only one subject with a clear artifact and no such behaviour for any other subjects, I would be tempted to remove it.
However I would also be very curious to know what it is about that subject’s data that is causing N4 to misbehave; maybe it could shed some light on how we could modify the default bias field estimation parameters to prevent such from occurring (this cerebellar hyperintensity has been a persistent issue since the introduction of this script). Any chance of sharing that one subject, along with a few from the same cohort where the bias field estimation succeeded, for a closer look?
I would like to post more screenshots here (for privacy issue).
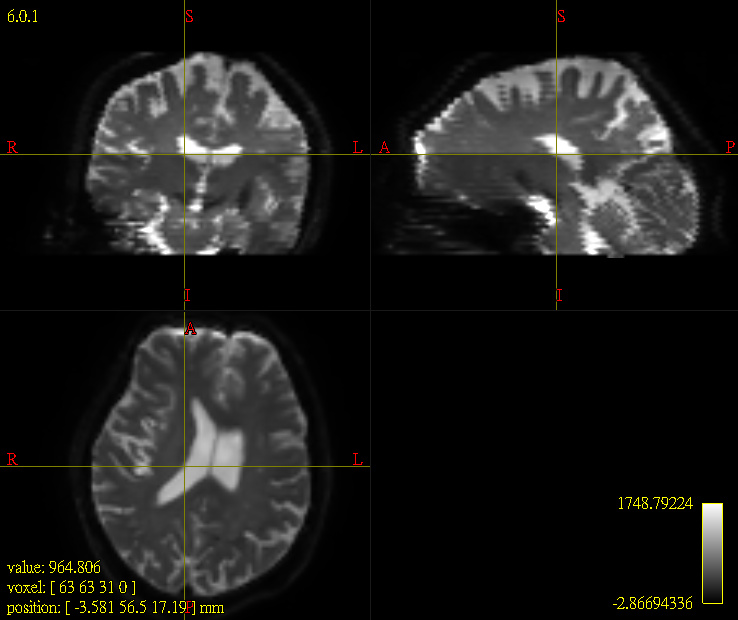
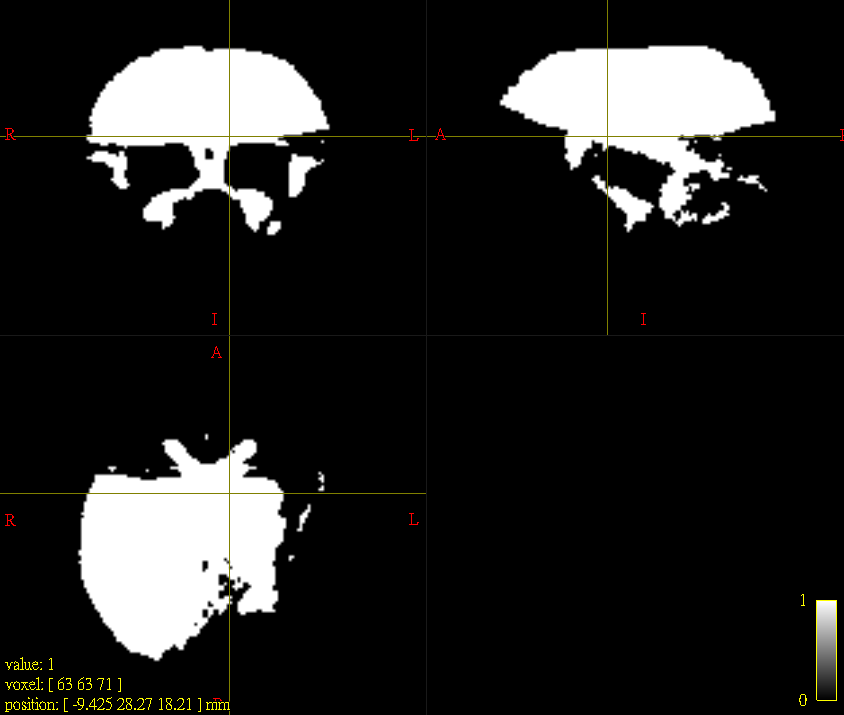
Our raw dwi images (b0 and b1000) were unfortunately scanned apart in 2 series, dividing the head/brain into upper portion and lower portion. So we tried merge them in the very first step and then go on following preprocessing steps. The inherent inhomogeneity of signals (intensity difference between the upper and the lower half) was obvious as you can see in the attached image (Fig 1, another subject). There might be many files corrupted in some way after the processing of N4 algorithm (Fig 2) and this may cause many of the lower parts excluded from the final group template mask (Fig 3). Thus we indeed need some kind of correction perhaps when doing the “merging” stuff. Any good suggestion?
Our raw dwi images (b0 and b1000) were unfortunately scanned apart in 2 series, dividing the head/brain into upper portion and lower portion.
Okay, dwibiascorrect is not going to be able to fix this. The fundamental assumption of all bias field correction algorithms is a smoothly-varying multiplicative field; what you have here is the antithesis of smooth.
If you want to be able to use such data, you are going to need to devise a solution that is tailored to this specific artefact. What you need is independent bias field correction of the two half-FoVs, then derivation of an appropriate scaling factor to apply when concatenating the two together. While it won’t work for your particular problem out-of-the-box, the concept behind new script dwicat might give some ideas as to how one might go about trrying to determine such a scaling factor in an automated fashion.