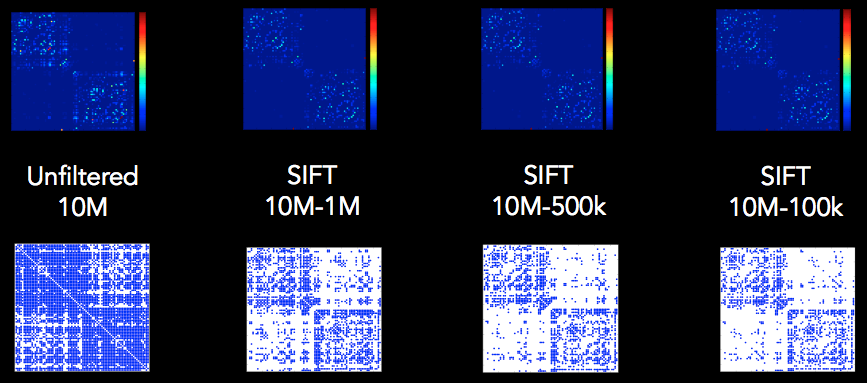
Top row: Weighted matrices by number of streamlines (NOS) Bottom row: Binarised matrices > 10 NOS for visualisation. At > 0 NOS, the networks were similarly and highly dense across the different levels of filtering.
Interestingly, a similar observation was made in your paper “Correction for diffusion MRI fibre tracking biases: The consequences for structural connectomic metrics” in Neuroimage 2016.
Regarding the denser nature of the networks:
"The rationale behind such a difference is the probabilistic nature and conservative estimates of orientation uncertainty of the iFOD2 algorithm (Tournier et al., 2010) that produce a widespread coverage of WM. "
Could you elaborate on this please? Thanks for your patience once
The comments in the Discussion section of that article were a bit of a follow-on from some points made in this paper, so that might be worth a read for you as well.
I’ll split this into two points:
Network density at > 0 NOS
Imagine you have two streamlines tracking algorithms at either ‘extreme’ of connectivity extent: One is fully deterministic, no orientation dispersion, and only represents one fibre orientation per voxel; the other is ‘so probabilistic’ that it’s completely random, with a purely spherical FOD in each voxel, and the streamlines just bounce around entirely at random, disregarding the DWI data.
For the first algorithm, there comes a certain point that no matter how many additional streamlines you seed, you will never see a connection that you haven’t already seen, no new edges will ever be added to the connectome, and the network density will never increase.
For the second algorithm, just about any trajectory through the white matter is possible. So at some point after an adequate number of streamlines have been generated, there will be at least one streamline connecting every single possible pair of nodes, and the network density will be 100%.
With MRtrix3 we get ‘network density’ values that are toward the upper end of this spectrum, because:
CSD is highly sensitive to crossing fibre populations, and so FOD-based tracking algorithms may permit reconstruction of minor pathways that could be omitted by other algorithms.
iFOD1 and iFOD2 sample directly from the FODs as the measure of fibre orientation dispersion / uncertainty. This is a relatively large angular range, even for the sharpest FOD ‘lobes’. Other probabilistic algorithms sample from the uncertainty in the peak orientation; but only the uncertainty in the peak orientation, which fails to take into account underlying fibre orientation dispersion (whether it’s measurable, incorporated in the diffusion model, or otherwise).
Network density is meaningless
I think @chunhungyeh made this point relatively well in that paper; but just to repeat the sentiment:
Axonal tracer studies show node-node connection strengths varying by over five orders of magnitude. No binary network, no matter how it is derived, will ever be accurately reflective of such a network, no matter how it is analyzed (unless your analysis happens to be ‘the number of connections stronger than a threshold’).
Even if you pre-suppose that some threshold must be defined, there is no possible threshold you can select that will produce a stable measure of network density; as a consequence, the ‘network density’ you measure will be a function of the threshold as much as, or more so than, the outcomes of the tracking experiment. Here’s the network density as a function of threshold:
I repeatedly see people getting stumped by the use of SIFT, because they’ve been ‘corrupted’ by the apparently compulsory use of binary networks in the diffusion MRI literature, and don’t see how to translate the use of MRtrix tools. I prefer to think that the brain structural connectivity is a weighted network, and SIFT/SIFT2/other comparable methods are simply the prerequisite tools the field has required to achieve reasonable estimates of those weights. Once you see both the data and the biology that way, there’s no reason to ever go back to a binary representation.
Though I’ve been told my opinions can be a little hard-line…
(I know! I was shocked too! )
Hi Elijah,
Reading this thread reminded me of this paper, where they plot (Fig. 1 and 4) the sensitivity and specificity of different tractography methods (including CSD). The results are likely to be heavily dependent on where each algorithm sits on this spectrum between deterministic and completely random probabilistic tracking.
Cheers,
Dave
FYI, this paper discussed the influence of fibre-tracking algorithm and parameter on graph density and metric, including some common deterministic and probabilistic methods (no iFOD2/ACT/SIFT though).

 )
)