I’m processing 7T MRI data with 60 directions, b=2500s/mm² with 7 b=0 volumes. I have ran all the required preproc steps to the DWI before computing the tensor.
After using dwi2tensor: dwi2tensor dwi_infoGrad.mif tensor.mif
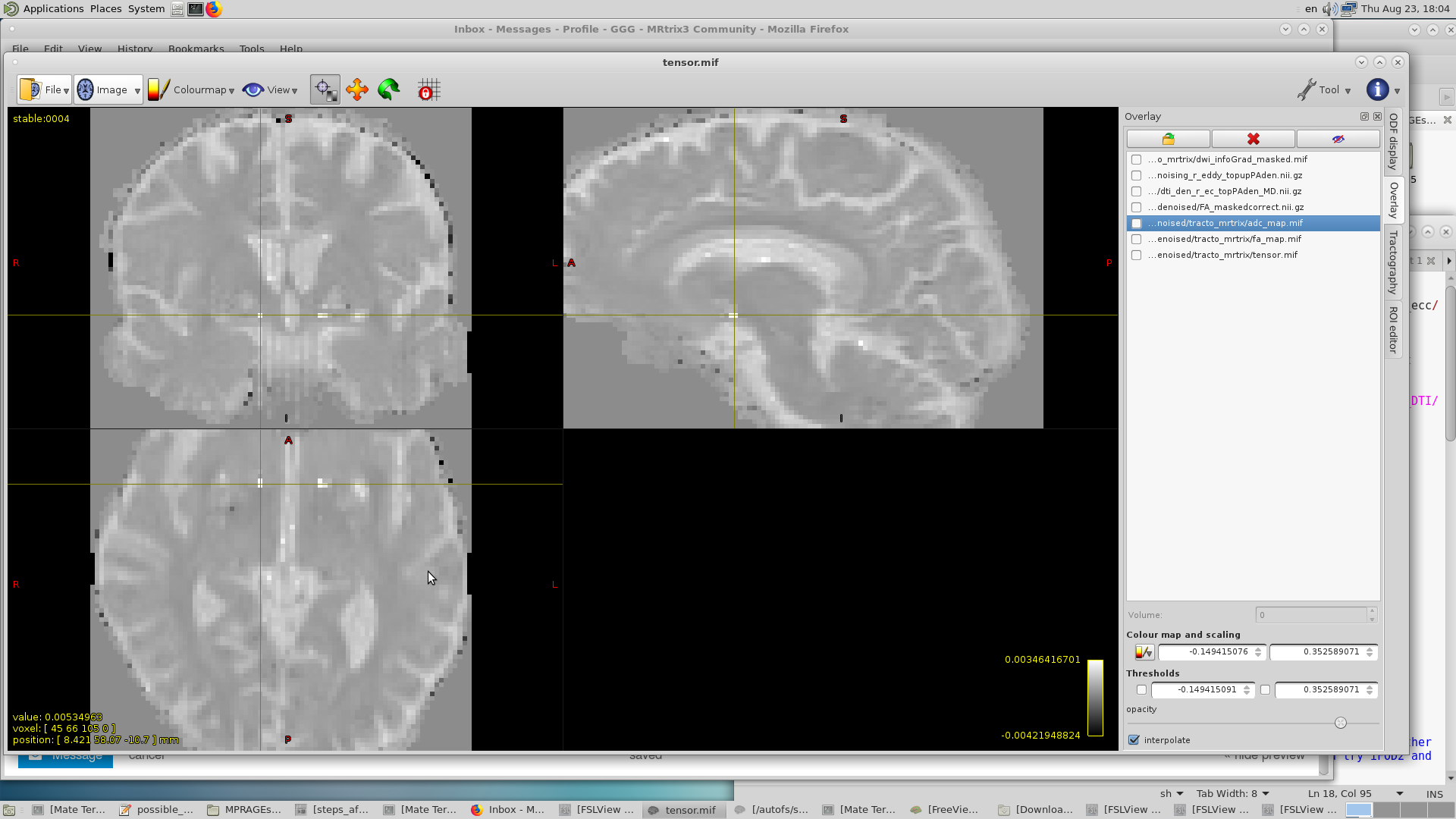
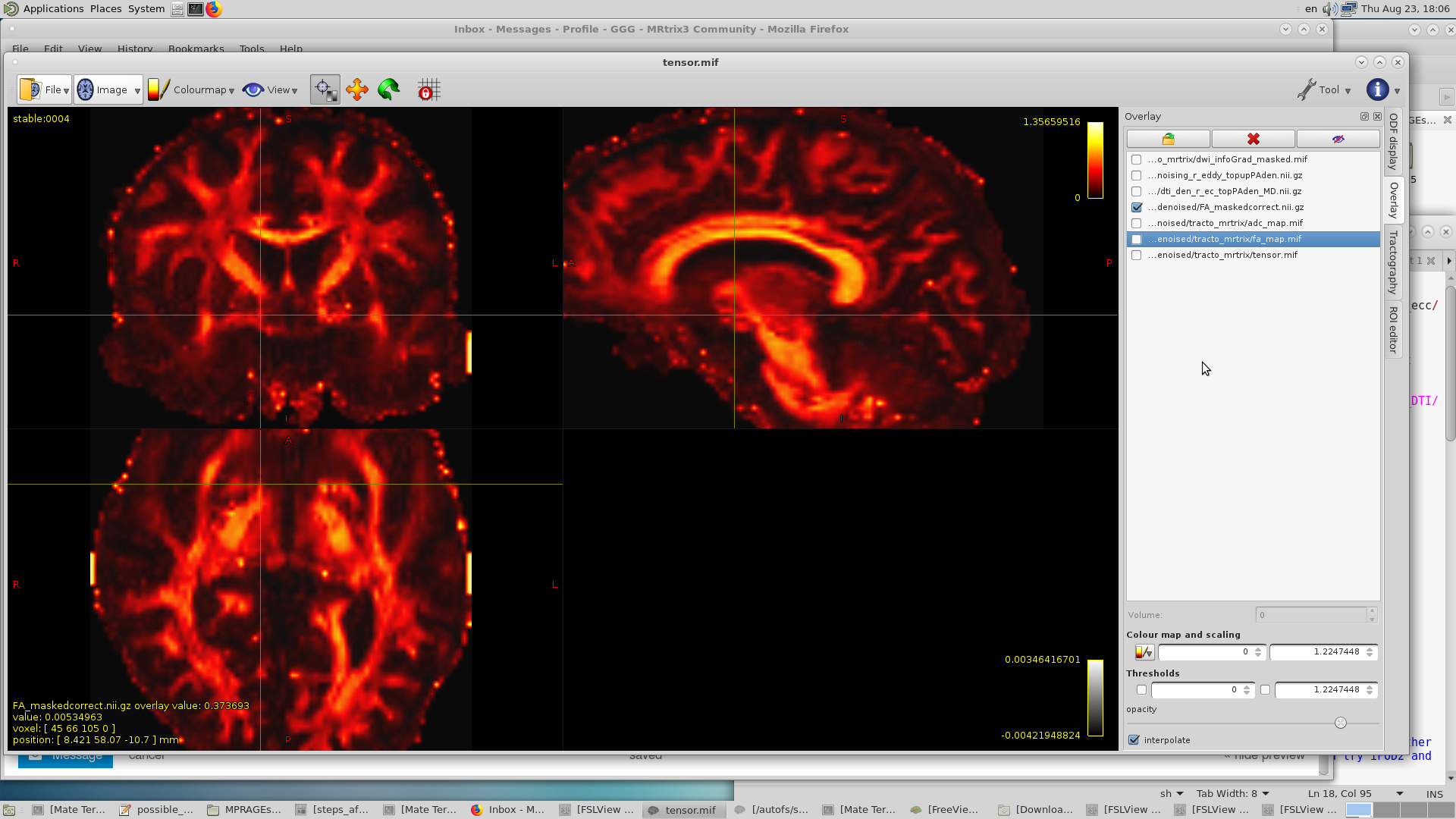
I looked at the first coefficient of the tensor.mif image and I got out of range values on some brain regions as you can see in this first volume of the tensor.mif (and is the same across all the 6 coefficients):
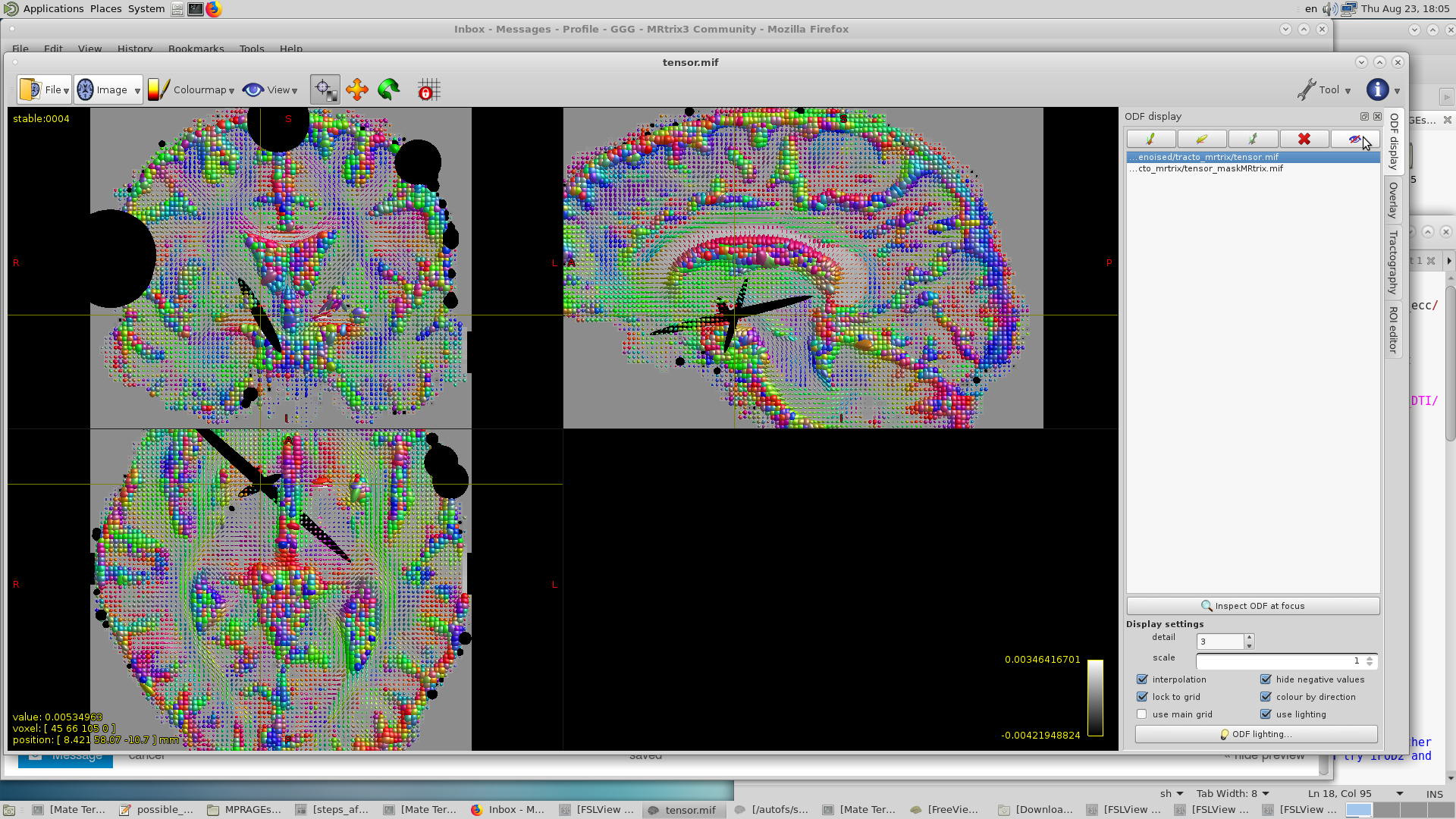
After looking at past discussions like this or this. I understood why I have negative values at the surface of the brain. Although I don’t understand what is happening within some voxels inside of the brain, like the one under the cursor.
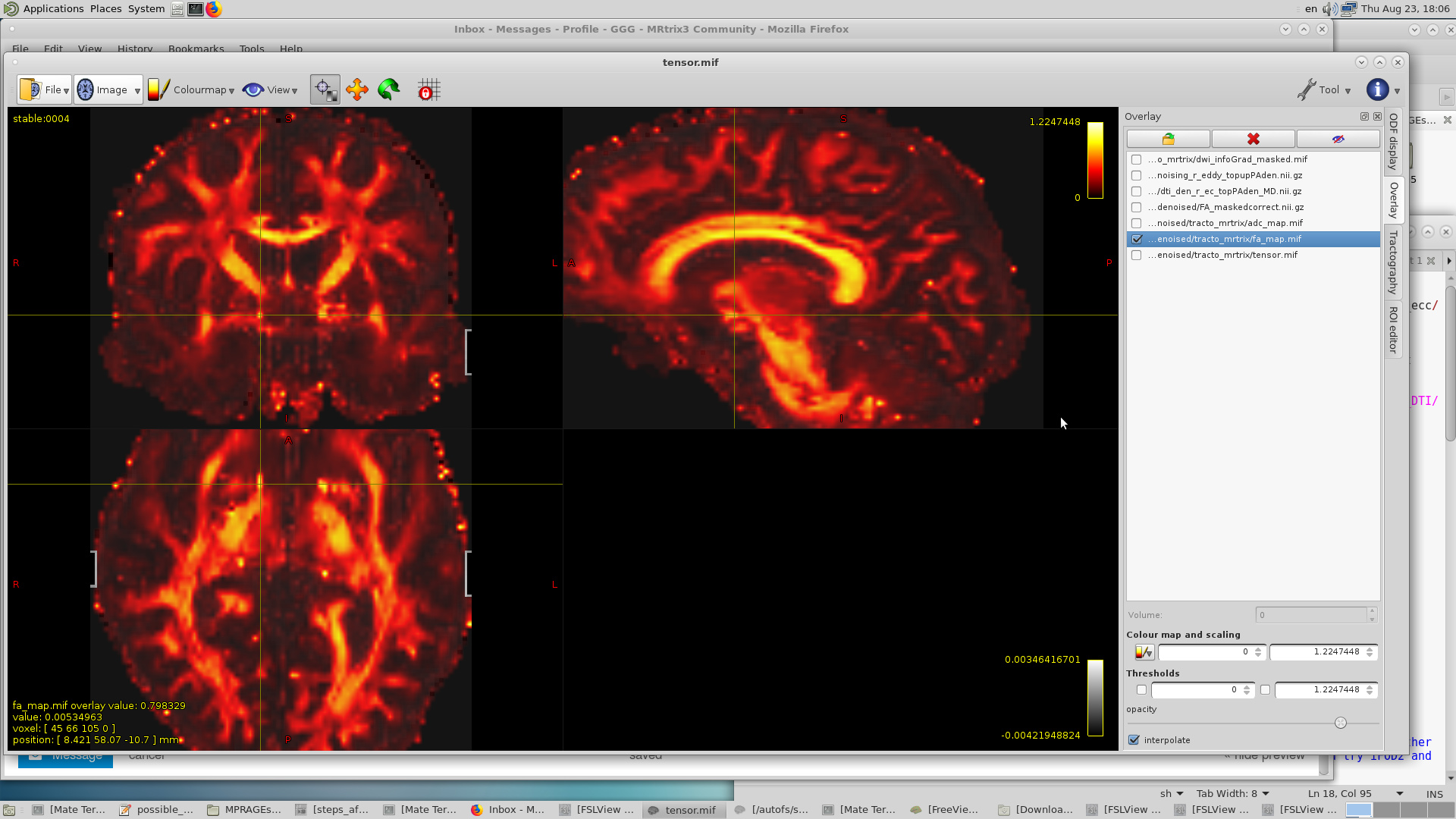
When I compute the FA map using MRtrix, I got very high values for that area as you can see:
It seems to me that the problem is essentially that the tensor estimated is not positive-definite – i.e. there are negative eigenvalues. This would explain the black glyphs being displayed in these locations. dwi2tensor uses a weighted least-squares fit, which doesn’t constrain the tensor parameters to be positive-definite. If dtifit imposes such a constraint, that would be enough to explain the discrepancy. You could verify with tensor2metric dt.mif -num 1,2,3 -value ev.mif, see if any of the eigenvalues at that location are negative.
As to what might be causing these issues: these typically boil down to the b=0 signal being lower than the DW signal in certain directions. This can often happen due to Gibbs ringing for example: voxels near CSF can often have lower b=0 signal than anticipated because of this, and this is often enough to cause problems of this nature. If you’re not already, you could try using mrdegibbs before your motion and eddy-current correction (i.e. dwipreproc), see if that helps.
I agree with the likely cause. I am just confused by the different dtifit result as its help page and source code suggest it is a simple linear or weighted linear fit.
if it’s also a simple linear fit, then indeed, I don’t see that this would make such a difference… Maybe they normalise to b=0 before the fit? In which case they could cap the ratio at a maximum of 1 prior to the fit, which would prevent such issues. It’s not how we do it, but I could see being a possibility. I guess we’d have to look at the FSL source code to be sure…
I’ll try to run mrdegibbs before running the preprocessing steps (I’m using the preprocessing directly from FSL) and see what is the outcome.
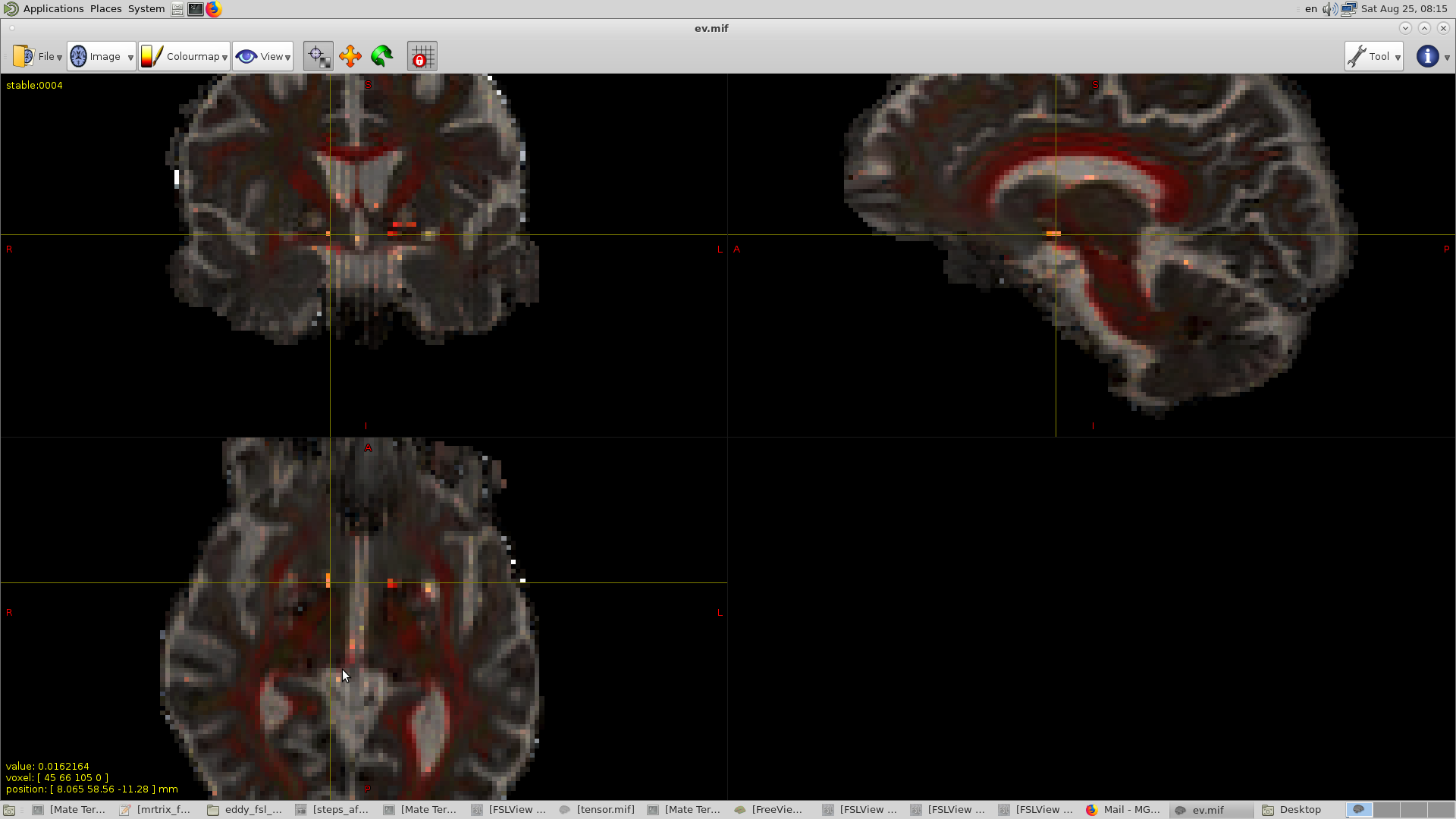
For now I tried to run the tensor2metric and the values of the same coordinates were actually considerably higher than the surrounding values, rather than being negative. As you can see:
Since the data are 7T, I implemented some preprocessing steps from different sources in order to improve the image quality. So I used denoise from other package. Then I ran topup with this command: topup --imain=AP_PAden_b0 --datain=acqparams.txt --config=myb02b0.cnf --out=my_topup_resultsPAden --iout=AP_PAden_b0_dc --fout=field_PAden -v
Then I import the bvecs and bvals to the image header for working with mrtrix: mrconvert dti_b2500_60dir_denoising_r_eddy_topupPAden.nii.gz dwi_infoGrad.mif -fslgrad eddy_rotated_bvecs bvalsMB_r2std.txt
Then I compute the tensor image: dwi2tensor dwi_infoGrad.mif tensor.mif -mask mask_nonclean.nii.gz
The same DWI image (dti_b2500_60dir_denoising_r_eddy_topupPAden.nii.gz ) was the input for both command of FSL and mrtrix (dtifit and dwi2tensor). I’m also confused by where this difference is coming from. Any help or suggestions for what to look at would be greatly appreciated.
The eigenvalue image you’re looking at is a 3-volume, 4D image. Look at the last volume (right arrow), this should correspond to the smallest eigenvalue. If any value is going to be negative, it’ll be that one…
If the issue is genuinely that the primary eigenvector is grossly over-estimated, then this would imply that the DW signal along that direction is ridiculously small – much smaller than expected even for free water… This might be due to a zero-value in your DW signals, which are difficult to deal with (you can’t take the log of zero…). The strategy in dwi2tensor is to set such small values to a millionth of the maximum signal in that voxel. I’m not sure how other packages might handle this… Maybe it would be better to ignore that value in the fit altogether (@bjeurissen, any thoughts…?).
I also note some consistent stripping in the coronal and axial planes. Were these images acquired in the sagittal plane? Otherwise I’d be concerned about where that might come from…
OK, I would suggest you run the processing without this denoising. The LPCA algorithm is probably harmless enough, and similar in spirit to what’s done in dwidenoise. The AONLM filter on the other hand definitely does have the potential to introduce bias. I’d like to see the results without this potential confound.
Note that the only reason I’m saying this is purely because I’ve no experience with the tools you’re using – I’m not saying they’re problematic, just that I’d like to rule them out as contributing factors here…
The 3th eigenvector is negative as you were thinking. So If I understand correctly, this is due to the least-squares fit algorithm that MRtrix uses to estimate the values, as it does not restrict the values to only positives? If this is the case would it require some sort of modification to the algorithm to prevent this, or is it possible to make a change simply in my data to prevent the black glyphs?
Yes the data have been acquired in sagittal plane, thanks for your thought.
I used LPCA algorithm for performing the denoising. I will rerun the preprocessing of the images using: dwidenoise, mrdegibbs and dwipreproc and see what the outcome is. Thanks for your suggestions and help.
It would require changes to the code. But more to the point, given @bjeurissen’s earlier comment, it’s still not clear why dtifit would give such different results. So we’d need to understand exactly what the cause is before considering whether we need to modify the tensor fitting code…
I ran dwi2tensor -iter 0 vs dtifit on my own data and FA maps were numerically identical throughout most of the brain, except for some isolated voxels mostly concentrated at the brain edge.
The relevant FSL code that likely causes this difference is:
for (int i=1; i<=S.Nrows(); i++)
{
if(S(i)>0)
logS(i)=log(S(i));
else
logS(i)=0;
}
Dvec=-Amat_pinv*logS; //Estimate the model parameters
if(Dvec(7)>-maxlogfloat )
s0=exp(-Dvec(7));
else
s0=S.MaximumAbsoluteValue();
for ( int i = 1; i <= S.Nrows(); i++)
{
if(s0<S.Sum()/S.Nrows()){ s0=S.MaximumAbsoluteValue(); }
logS(i)=(S(i)/s0)>0.01 ? log(S(i)):log(0.01*s0);
}
Dvec = -Amat_pinv*logS;
So the ordinary least squared fit is performed twice in FSL, the second time with the input data modified.
Note that this compares the OLS implementation of both software packages. WLS versions cannot be directly compared as our WLS is based on (iterative) model predictions and not on raw data as is the case for FSL.
So looking through this, there’s a few differences between the FSL implementation and ours (with -iter 0 – otherwise there’s also the fact that ours is iteratively reweighted…). But to cut a long story short, the only difference is the way they handle small DW signals:
dtifit: DW signals are clamped at 1% of the predictedb=0 signal. The fit in the first pass is there to predict the b=0 signal, and fix it up if it’s unrealistic for some reason.
dwi2tensor: DW signals are clamped at 1e-6 × the max DW signal in that voxel.
There’s no right answer here as to how to handle small or negative DW intensities. But dtifit definitely makes stronger assumptions: it already kicks in with CSF at b=3,000 s/mm²… This might very well introduce differences between our implementations. But I find their handling too restrictive for a general-purpose tensor fit: this definitely won’t be suitable for high b-value data and/or high diffusivity voxels, where that ratio should theoretically be smaller. It should be fine for b=1,000 s/mm² though: the ratio for free water would then be exp(-bD) ≈ 5% (even assuming D=3,000 mm²/s).
So all in all, I think the differences in implementation are sufficient to explain the discrepancies, but there’s nothing in their implementation that would prompt me to change how we do the fit, I don’t think… Any opinions on this?
Fully agreed. I’m personally quite happy with the general robustness of the iteratively reweighted fit.
Wow, that’s an (overly) strong constraint, that by definition would indeed affect CSF / free water at b=3000 s/mm². Not sure about the impact on “pure-ish” WM though… I don’t really know typical values of axial diffusivity for highly coherently oriented WM off the top of my head. Maybe somewhere in the range of 1,000 ~ 1,500 mm²/s or something? But well, in any case, such a strong constraint shouldn’t be needed in the first place, I reckon.
Inspired by some loosely related work (can clarify privately if necessary / curious):
I personally think that such non-physical intensities are best omitted from the model, rather than trying to fill them with data that are both non-informative and compatible with the impending log transform. So for each voxel, one would identify the set of DWI volumes that contain strictly positive intensities, and if this is not the complete set of all input DWI volumes, it is then necessary to re-derive a new tensor inverse model just for that voxel, based on only the b-values / directions of those DWI volumes for which data are available in that voxel.
Obviously this is more computationally expensive than having a fixed universal inverse model, would require someone putting development time into improvement of tensor model fitting, and would potentially have biases of its own; but I wonder if it would be less biased than filling such volumes with arbitrary values.
Actually, what you’re describing would be relatively trivial to incorporate into the current implementation. It’s doing a weighted fit, so it’s perfectly feasible to set the weights to zero for intensities that are non-physical. It might not always be a good idea (particularly if the number of DW volumes is low), but certainly feasible – along with outlier rejection: in both cases, all we need to do is to set different weights than we currently do (based on SNR considerations only ATM).
I have found with my data that these errors occur only when I run FSL’s topup function on my data before fitting tensors using dwi2tensor. Topup produces several negative values in the resulting images, which correspond to the same locations as the “black hole” tensors.
When running only eddy and omitting topup, this problem is resolved (though now the data is not susceptibility-corrected). I noticed that previous discussions assumed that these negative values came from the tensor fitting process, but in my experience they came from topup.
I’m not sure what the specifics of the topup algorithm are that lead to these issues and negative value estimations, but I thought I would add this observation here in case it helps anyone!Any alternative recommendations to topup are also appreciated.
topup (and utilisation of its field estimate in eddy) can indeed produce negative output values despite non-negative input values. This occurs if the estimated susceptibility field is non-diffeomorphic (whether or not the actual distortions are diffeomorphic), which leads to negative values of the Jacobian. The other corrections performed within eddy are pretty much guaranteed to not produce this effect as the spatial frequencies involved are far lower and the basis in which they are represented is different.
While it makes perfect sense to use e.g. “mrcalc DWI.mif 0.0 -max” to clamp negative DWI intensities at zero, that doesn’t actually resolve this specific issue entirely, as 0.0 is still incompatible with the logarithmic transform involved in the tensor fit / weighting.
Definitely a common root cause of the issue though, so well worth including in the discussion
 if it’s also a simple linear fit, then indeed, I don’t see that this would make such a difference… Maybe they normalise to b=0 before the fit? In which case they could cap the ratio at a maximum of 1 prior to the fit, which would prevent such issues. It’s not how we do it, but I could see being a possibility. I guess we’d have to look at the FSL source code to be sure…
if it’s also a simple linear fit, then indeed, I don’t see that this would make such a difference… Maybe they normalise to b=0 before the fit? In which case they could cap the ratio at a maximum of 1 prior to the fit, which would prevent such issues. It’s not how we do it, but I could see being a possibility. I guess we’d have to look at the FSL source code to be sure…