Hi all,
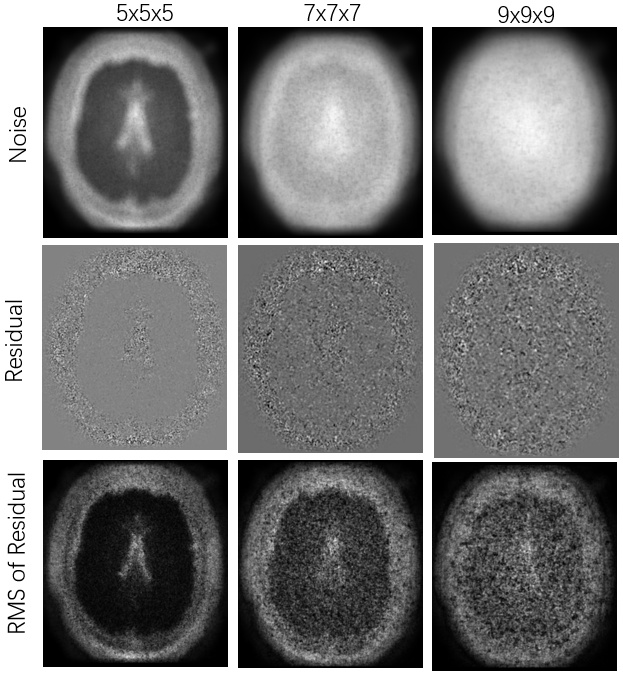
I’m runing dwidenoise on my data(8 b0 + 96 b2000, repeat twice, in total 208 volumes). I am not sure what extent is better for the data. So I have run it with three extent sizes(5, 7, 9) and got some results(see bellow images). Could you please offer me some suggestions on this? thanks.
For me, I would like to pick 7x7x7 for two reasons:
1, it shows little anatomy.
2, it captures the variability of the noise between brain and out-brain.
But I am not sure about this.
Zonglei
Yes, I think that looks about right too. The 5x5x5 case doesn’t look like it denoised very much. 7x7x7 seems to perform much better, and will be much faster to compute than the 9x9x9 case.
Hi Donald @jdtournier,
Thanks for your comments. Two further questions.
1, The unit for the extent is voxel, not mm. so if I have different resolution in x, y,z, I should give different number in each dimension. for example, if my voxel size is 1 x1 x 2, I should assign the extent as 9x9x5 to make a 10mm x10mm x 10mm windows. Am i right?
2, I have two runs data which were collected in different sessions. The parameters for the two runs is totally the same, but they are not aligned in space. If i want to combine them together to do denoise, What is the best option for me? can i directly concate them without do alignment ? The mannual told us: don’t do anything before dwidenoise.
The assumption of the method used in dwidenoise is that in a local patch the noiseless signal is sparse and can be represented using a low dimensional projection of the measured signal. Noise on the other hand is not sparse. I think, for this decomposition, the actual size of the voxels should matter much less than the extent in voxels.
If you go for concatenation and splitting, you can use mrconvert's -set_property and -get_property to manually set the transformations back to their original values.
Hi @maxpietsch
Sorry, I am not sure I understand what you mean exactly.
1, Did you suggest that the voxel size does’t matter in setting extent?
2, My data is a test-retest data, so they should share the same noise characteristic. My question is should I align them before concatening them or just directly concatenate them without the alignment. As you explained that dwidenoise rely on local patch information rather than the whole aligned image. So, I guess I can concatenate them directly? But after denoise, I should reset the prooerties for each set. yes?
Thanks,
Zonglei
what matters is that there are enough independent voxels in the neighborhood to figure out the redundancy in the signal. So as long as the noise in those voxels can be assumed independent, it shouldn’t matter what shape they are. The shape of the overall neighbourhood also doesn’t matter all that much, as long as it’s close enough to the voxels of interest that the noise properties can be assumed identical. So I’d stick with an isotropic neighbourhood in voxels space (the default). But by all means, try different shapes and see whether it checks out – and do report back if you find anything unexpected.
If your data were acquired in different sessions, I would not concatenate them, no matter how well aligned they might be. There’s lots of reasons for the noise level to vary between sessions, which would break the assumptions of the MP-PCA denoising approach…
Thanks for your comments, Donald @jdtournier
Then I have a further question. If we can not concatenate the data from different sessions. if I still want to combine the data from the two sessions, How to do this?
Can I denoise it separately, and then concatenate and align them to do tractography? can you give me some suggestions on this?
Zonglei
Thanks for this discussion, I am also trying to optimize this part of my pipeline. Is there a reason you wouldn’t recommend the 9x9x9 kernel over the 7x7x7? Is it because it’s computationally intensive? It seems to be doing a better job from what I understand.