Due to many experts’ help, now I can make my own script although it is incomplete. however, now I can not help asking you one help again.
I have been trying group intensity normalization with “dwiintesitynorm command”.
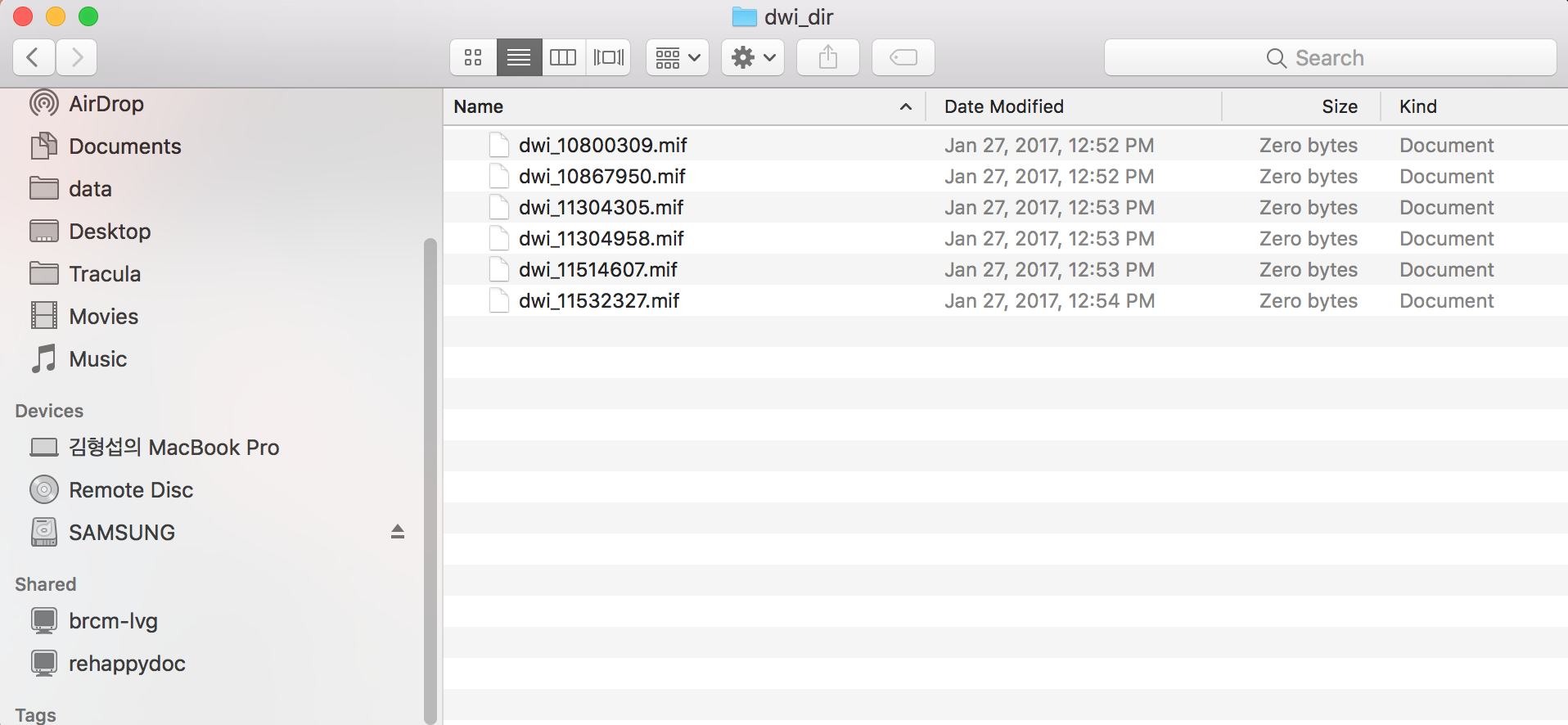
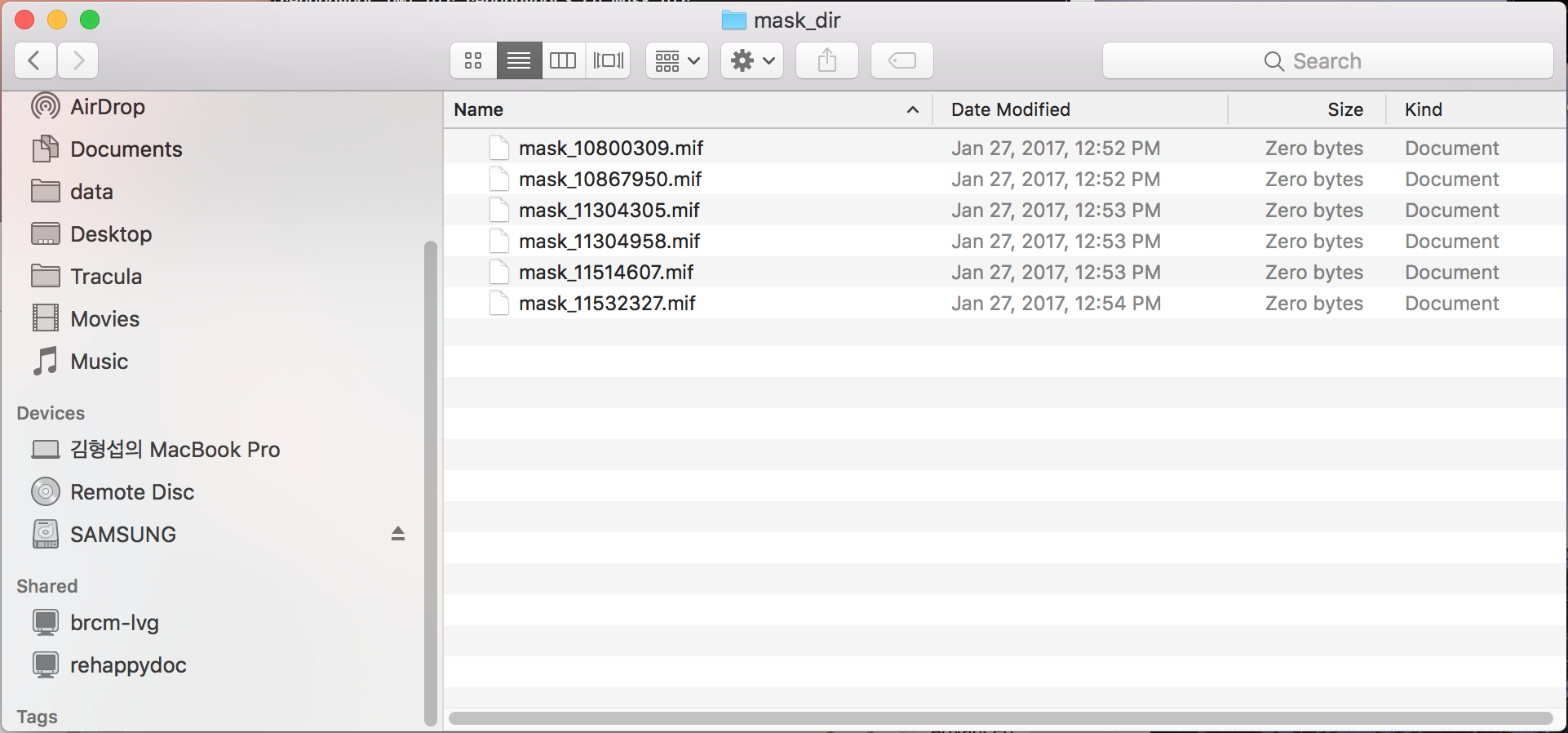
there are six files in both dwi_folder and mask_folder. You can see them in the attached files.
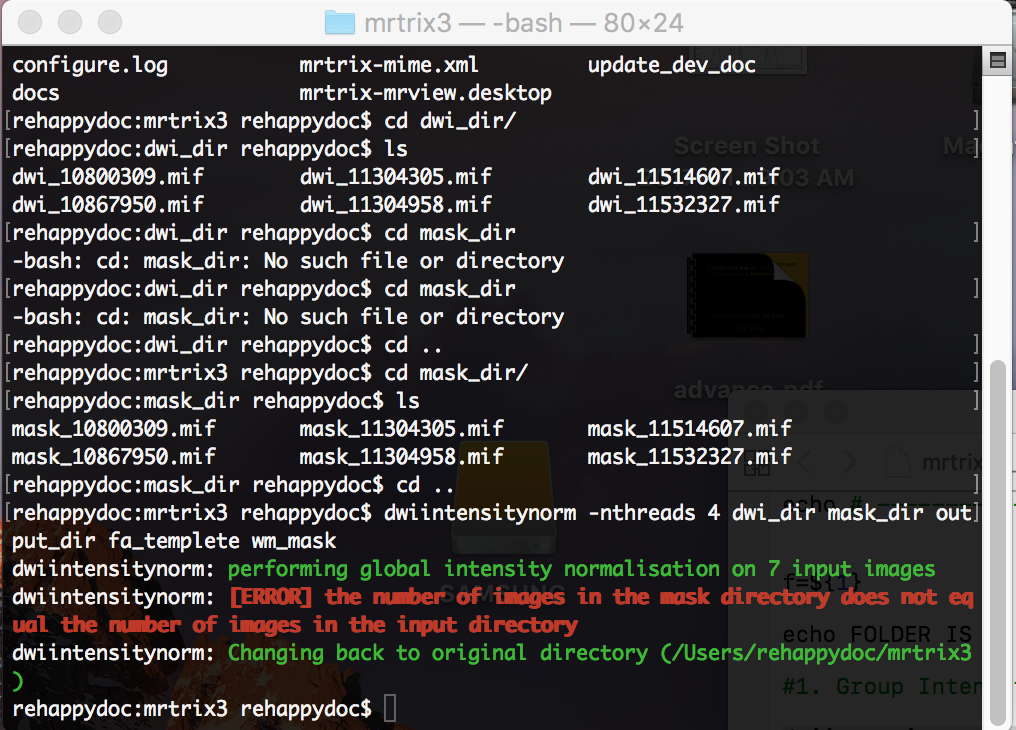
I type the command " $ dwiintensitynorm -nthreads 4 dwi_dir mask_dir output_dir fa_templete wm_mask"
But until now, I can see the Error message.
dwiintensitynorm: performing global intensity normalisation on 7 input images
dwiintensitynorm: [ERROR] the number of images in the mask directory does not equal the number of images in the input directory
my computer insists that there are 7 files in the “dwi_dir folder”
Hi,
That’s a weird one. The only thing I can think of is maybe you have a hidden file inside the dwi folder? It’s also odd that the file browser is reporting ‘zero bytes’.
I notice this is on a backup drive? Presumably an external NTFS formatted drive? It might have something to do with this, MacOSX (which I presume is what you’re running this on) has a habit of adding hidden __MACOSX folders when manipulating ZIP archives (see e.g. this article on the topic). It could be that this is what happened?
Your comments were right! There was a hidden file in the dwi_folder.
so in a terminal window, I typed ls -all. After removing a hidden file, I can run group normalization. However, it takes a lot of time.
I believe the error message is slightly misleading, and the script is in fact unable to find the corresponding mask file for any of the input files; it’s just printing the error for the file that it happens to look for first.
The dwiintensitynorm help page states (emphasis mine): Input directory containing brain masks, corresponding to one per input image (with the same file name prefix)
I would suggest that the current code within dwiintensitynorm is able to determine the correspondence between input and mask images only when the unique identifier for each subject appears at the start of the filename. Obviously this could be improved by implementing improved logic within the source code for determining that correspondence, but this script has generally fallen out of use in favour of mtnormalise.