Hi all :
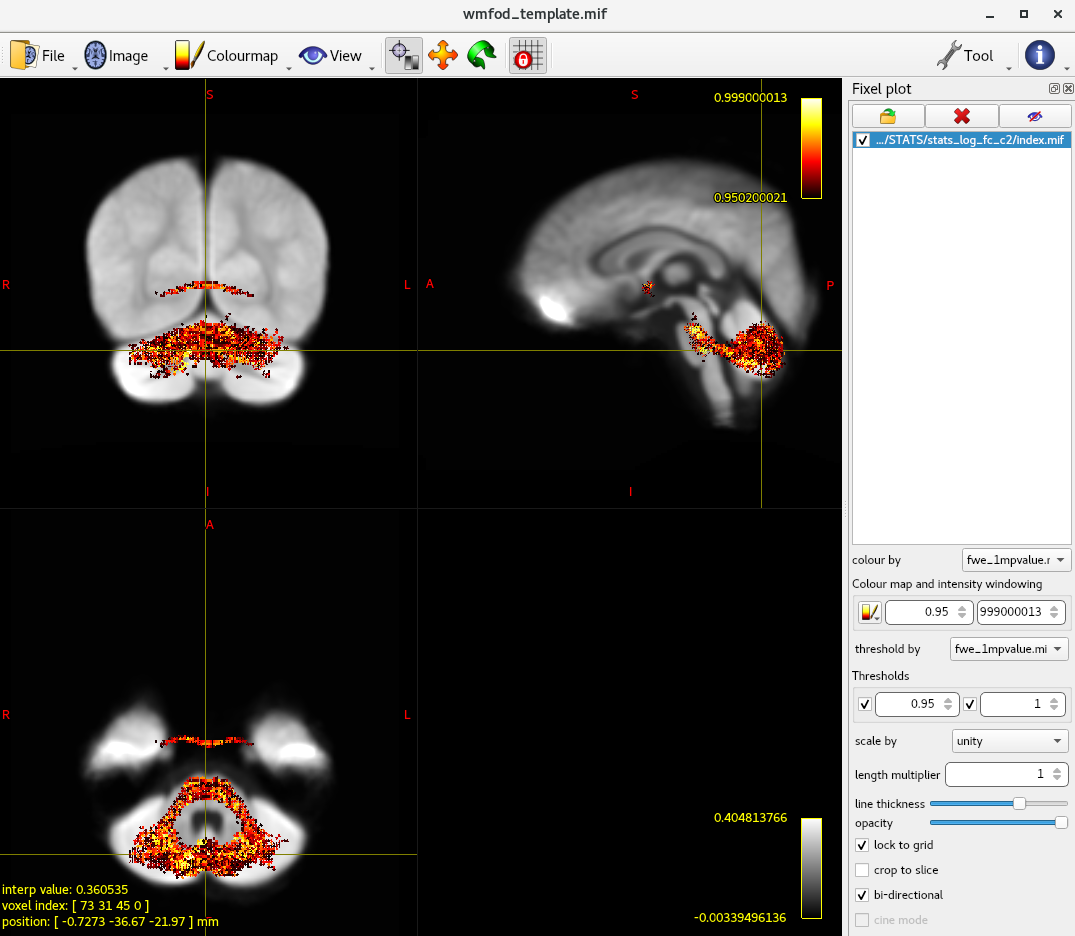
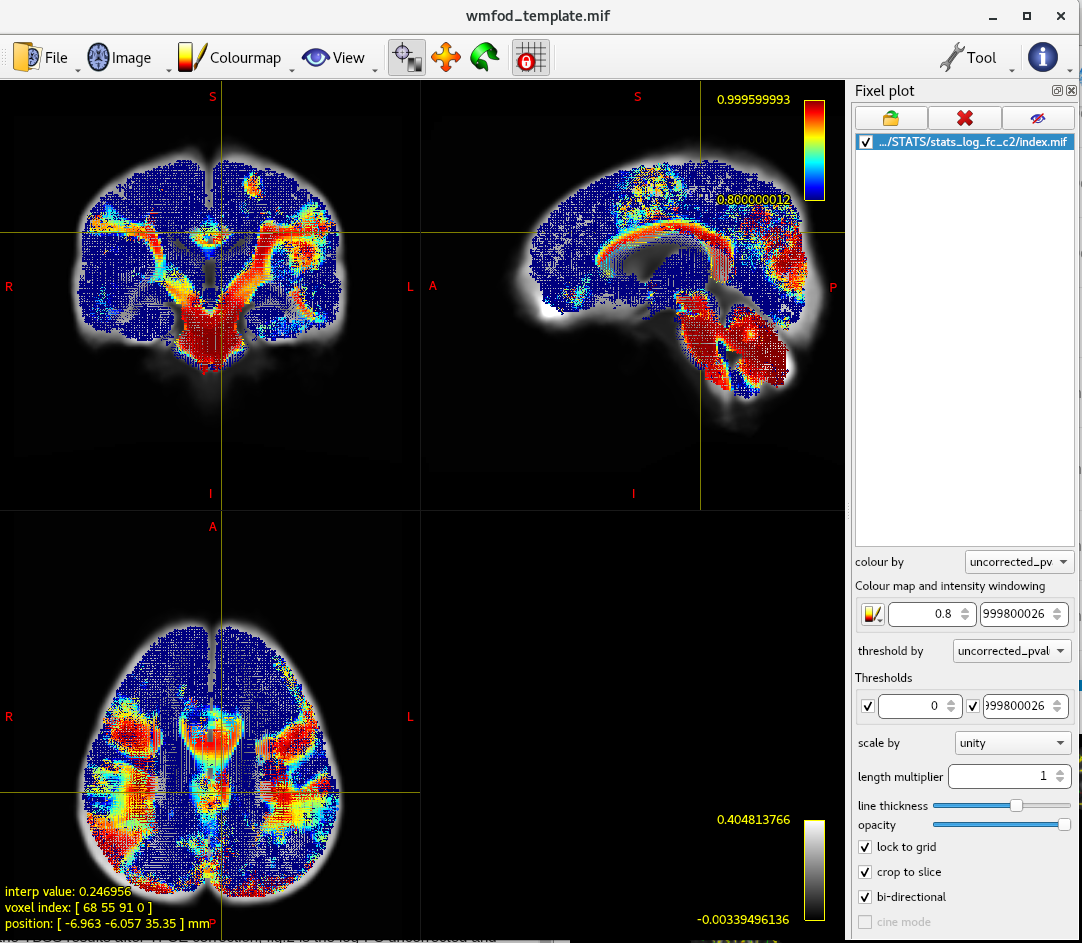
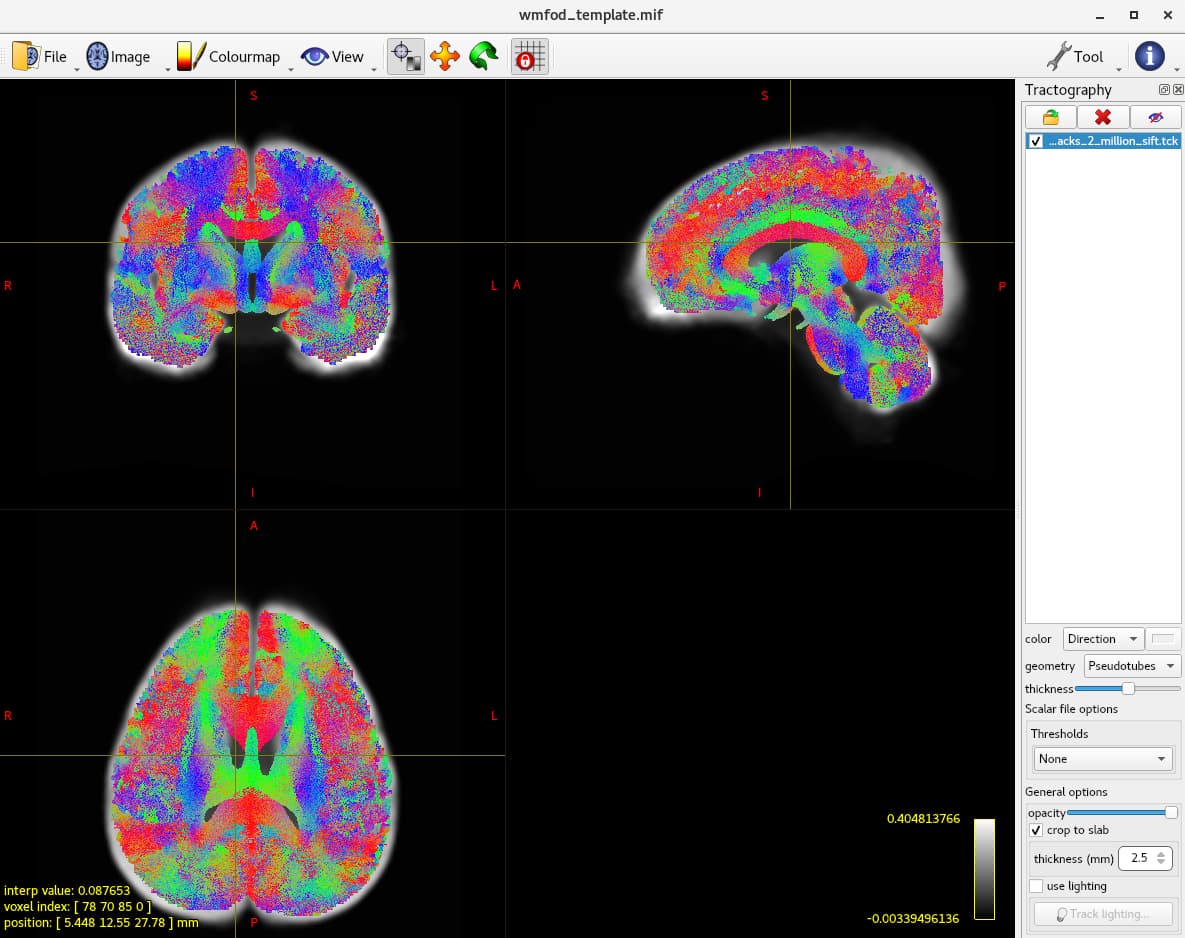
I have performed the FBA analysis follow the pipeline “Fibre density and cross-section - Single-tissue CSD”. After the fod group template has generated, I extract the FA map from all of the subjects and perform the TBSS analysis. The TBSS results showed a global reduction of FA (TFCE,p<0.05). However, when I run the fixelcfestats for FD,log-FC,and FDC. Only the log-FC was significant reduced in the cerebellum. Is it reasonable ? Fig.1 is the TBSS results after TFCE correction, fig.2 is the log-FC uncorrected and corrected map. Fig.3 is the whole brain tractogram after sift filter.
The data are come from children (age 4-10 years old) with neurodevelopmental disorder, and I think the whole brain axonal impairment is correct. Could you please take a look about my results?

Hi :
The differences between TBSS and FBA is mainly depend on my design matrix. Firstly, I use fsl-glm to build a design matrix for TBSS analysis and then apply it in fixelcfestats. In FSL, the group factor is divided into two columns. But for FBA, it is better to combine them into one column to avoid matrix rank deficiency.
The covariates such as the TIV(~1500mm3) usually much greater than the other factors (age:5). This also generate noise in the design matrix. I used z-score to reduce the matrix condition number from 500 to 2 and finally solve the problem. Thanks for the answer by rsmith.GLM
Now, I can get the expected results from TBSS and FBA.
Hi @ray,
Even though you’ve seemingly resolved the issue, I’m nevertheless curious about exactly what it was that made a drastic difference to your outcomes. If it was indeed an issue of rank deficiency due to construction of the group variables, that’s a possibility, though it would be clearer if examples of the actual design & contrast matrices were provided in order to verify that that was in fact a problem. Conversely, if just the act of Z-transforming the TIV variable was on its own sufficient to go from a null result to a plausible result, then I may need to reconsider how the software behaves under such scenarios; either by issuing warnings to users, or indeed by automatically Z-transforming all variables internally within the code.
Thanks
Rob
Hi rsmith:
Thanks for your reply ! Here is my original design matrix
1 0 5.89 0 1288.17276856 0 1
1 0 8.39 1 993.325830751 0 1
1 0 7.35 0 1189.17397927 1 1
1 0 5.91 1 1297.58071194 0 1
1 0 9.18 1 1185.45781732 1 1
1 0 7.53 1 1175.5161637 1 1
1 0 6.45 1 1310.54366141 1 1
1 0 6.5 0 960.734596577 0 1
1 0 5.89 0 1108.36477302 1 1
1 0 4.98 0 1146.34804813 0 1
1 0 7.16 1 1239.01178194 0 1
1 0 5.32 0 1054.30066831 1 1
1 0 5.18 0 1227.77748467 0 1
1 0 7.71 1 1072.53628834 1 1
1 0 8.18 1 920.005290624 0 1
1 0 4.96 1 1100.5390383 1 1
1 0 6.72 0 1196.47889302 1 1
1 0 5.22 1 1033.53027851 0 1
1 0 4.84 1 1017.11888512 0 1
1 0 5.48 1 1110.6743856 1 1
1 0 5.38 0 1206.41599823 1 1
1 0 5.1 0 1199.82123539 0 1
1 0 6.18 0 1110.6541555 0 1
1 0 6.47 1 1164.83233362 1 1
1 0 7.6 1 1087.48257761 0 1
1 0 7.37 0 1062.6933558 0 1
1 0 7.73 0 946.024378918 0 1
1 0 8.45 0 1135.3388038 1 1
1 0 9.41 0 1113.73176605 0 1
1 0 9.56 0 1367.49740519 1 1
0 1 8.67 0 1627.89031051 1 1
0 1 7.38 0 1593.40434273 1 1
0 1 7.45 0 1254.28790213 1 1
0 1 6.38 0 1415.50781392 0 1
0 1 8.56 0 1585.49415846 0 1
0 1 9.3 0 1259.19640824 1 1
0 1 10.28 0 1406.23825522 0 1
0 1 5.12 0 1456.81548021 1 1
0 1 7.16 0 1302.18587847 0 1
0 1 5.35 0 1379.76589396 1 1
0 1 7.32 0 1425.70505766 0 1
0 1 5.16 1 1410.85177982 0 1
0 1 5.8 0 1231.73119665 1 1
0 1 6.38 0 1365.71047195 0 1
0 1 5.13 0 1159.84174161 0 1
0 1 8.35 0 1594.24421516 1 1
0 1 5.66 1 1440.71041666 1 1
0 1 7.12 1 1170.15271129 0 1
0 1 7.12 1 1207.70395921 0 1
and after adjust, it looks like :
1 0 -0.666368928470151 0.328102271380661 1
1 0 1.06418425655409 -1.35801548117115 1
1 1 0.344274131584005 -0.238034237763405 1
1 0 -0.652524502989957 0.381902729563802 1
1 1 1.61103906302175 -0.259285557793432 1
1 1 0.46887396090575 -0.316138102313538 1
1 1 -0.278725015024721 0.456032918567012 1
1 0 -0.244113951324237 -1.5443923821039 1
1 1 -0.666368928470151 -0.700151423854075 1
1 0 -1.29629028781897 -0.482939486911668 1
1 0 0.212752089522163 0.046969243888816 1
1 1 -1.06093505465568 -1.00932352312954 1
1 0 -1.15784603301704 -0.017275439149616 1
1 1 0.593473790227495 -0.905040931999865 1
1 0 0.918817789012052 -1.77730782740846 1
1 1 -1.31013471329917 -0.744903831107158 1
1 1 -0.091825271042104 -0.196260208003212 1
1 0 -1.13015718205665 -1.12810150071155 1
1 0 -1.39320126618033 -1.22195203192146 1
1 1 -0.950179650814126 -0.686943625931554 1
1 1 -1.0194017782151 -0.139433674113924 1
1 0 -1.21322373493781 -0.177146620298891 1
1 0 -0.46562475900734 -0.687059314196793 1
1 1 -0.264880589544528 -0.37723487237667 1
1 0 0.517329450086429 -0.819568775293098 1
1 0 0.358118557064199 -0.961328928124874 1
1 0 0.60731821570769 -1.62851453484883 1
1 1 1.10571753299467 -0.545897177586475 1
1 0 1.77024995604398 -0.669459627313977 1
1 1 1.87408314714543 0.781729767160208 1
-1 1 1.2580062132768 2.27081798208686 1
-1 1 0.365040769804296 2.07360581865088 1
-1 1 0.413496258984975 0.134327578467008 1
-1 0 -0.3271805042054 1.05628307630585 1
-1 0 1.18186187313574 2.02837047646719 1
-1 1 1.69410561590291 0.16239746229243 1
-1 0 2.37248246443241 1.00327398759517 1
-1 1 -1.19937930945762 1.29250594490886 1
-1 0 0.212752089522163 0.408237929438662 1
-1 1 -1.04016841643539 0.85188859894526 1
-1 0 0.323507493363714 1.11459724373414 1
-1 0 -1.17169045849723 1.02965698410074 1
-1 1 -0.728668843131024 0.005334339359508 1
-1 0 -0.3271805042054 0.771510974043419 1
-1 0 -1.19245709671752 -0.405774174315275 1
-1 1 1.0364954055937 2.07840873037391 1
-1 1 -0.825579821492381 1.20040719781175 1
-1 0 0.185063238561775 -0.346809651391405 1
-1 0 0.185063238561775 -0.132068314008408 1
the columns include group, sex, sex, scanner, intercept. When I use the first design matrix, it returns the warning:
fixelcfestats: Number of fixels in template: 997303
..done
fixelcfestats: Number of fixels in template: 997303
fixelcfestats: Importing data from files listed in "subjects.txt" as found relative to directory "fd_smooth/"... done
fixelcfestats: Number of inputs: 49
fixelcfestats: Number of factors: 7
fixelcfestats: [WARNING] Design matrix is rank-deficient; processing may proceed, but manually checking your matrix is advised
fixelcfestats: Number of hypotheses: 1
fixelcfestats: [WARNING] A total of 113211 fixels do not possess any streamlines-based connectivity; these will not be enhanced by CFE, and hence cannot be tested for statistical significance
This is the output for last attempt, I delete the variable ‘scanner’.
fixelcfestats: [WARNING] existing output files will be overwritten
fixelcfestats: Number of fixels in template: 997303
fixelcfestats: Importing data from files listed in "subjects.txt" as found relative to directory "log_fc_smooth/"... .....done
fixelcfestats: Number of inputs: 49
fixelcfestats: Number of factors: 5
fixelcfestats: Design matrix condition number: 3.21042
fixelcfestats: Number of hypotheses: 1
fixelcfestats: [WARNING] A total of 113211 fixels do not possess any streamlines-based connectivity; these will not be enhanced by CFE, and hence cannot be tested for statistical significance
fixelcfestats: Loading fixel data (no smoothing)...
I also tried to delete the intercept 1 and scanner at the same time, but it gave me a much larger condition number than any time. In this test, the group is divided into two columns.
fixelcfestats: Number of inputs: 49
fixelcfestats: Number of factors: 5
fixelcfestats: [WARNING] Design matrix conditioning is poor (condition number: 19643.5); model fitting may be highly influenced by noise
fixelcfestats: Number of hypotheses: 1
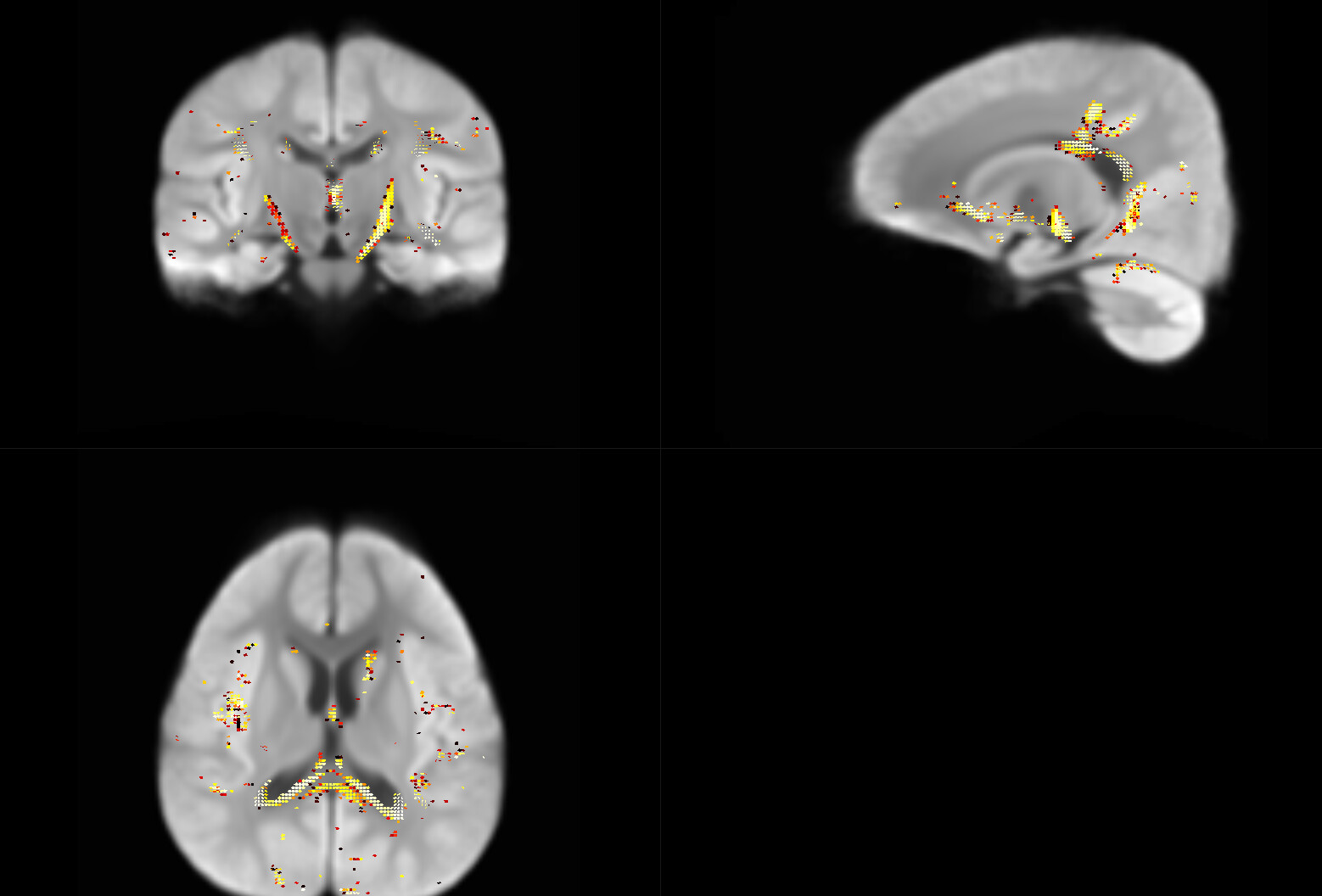
This is my FD output after adjust. I also used nonstationarity to correct the results. I found there are too many small fixel cluster in the result.
I’m sorry I found the condition number is different from I reported here. ![]()
ray
Here is my original design matrix
fixelcfestats: [WARNING] Design matrix is rank-deficient; processing may proceed, but manually checking your matrix is advised
That makes sense: if you use two columns to encode group membership, i.e. first two columns are 1 0 for first group and 0 1 for second group, then you cannot then additionally have a global intercept column containing all 1’s (last column in your case). The summation of the first two columns is equivalent to the global intercept, and therefore it’s impossible to determine unambiguously what the beta coefficients should be. Note that rank deficiency can be thought of as having a condition number of infinity; not sure if that makes things more or less confusing, but the two types of feedback are strongly related.
I also tried to delete the intercept 1 and scanner at the same time, but it gave me a much larger condition number than any time.
There’s more variables at play here than what you have provided data for. I see no reason why the “scanner” variable would need to be eliminated, whereas if you have group membership across two columns, the global intercept should absolutely be eliminated. What I would have expected to have the effect of decreasing the condition number from ~ 20k to ~ 3 is the Z-transforming of the TIV. What I’m interested in is whether that last change just results in removal of a terminal warning, or drastically changes the statistical power; because if the latter, it warrants something louder than the existing warning.
I also used nonstationarity to correct the results.
I would advise against using this for all but the highest quality data. Indeed this may well be the reason for your many small fixel clusters. I invested some time into trying to improve the empirical non-stationarity correction for fixel data, but could never get it to work better than the intrinsic non-stationarity correction that occurs by default in 3.0.x (and, indeed, explicit use of the former effectively circumvents the latter). See results here.
Rob
Hi rob:
Really thanks for your reply. I have learned too much from that. I tested if the Z-trans variables would benefit the results. I added the scanner to the model and compared the results between Z-trans and no Z-trans. Only a few changes were found between these two models. I think the additionally intercept seems explained too much than group variable.
I have another small question about the significant clusters. After removed -nonstationarity options, there are still many small fixel clusters exist in results. I wonder if there are some additionally processes to improve the results.
Result with no-Ztrans fdc comparison
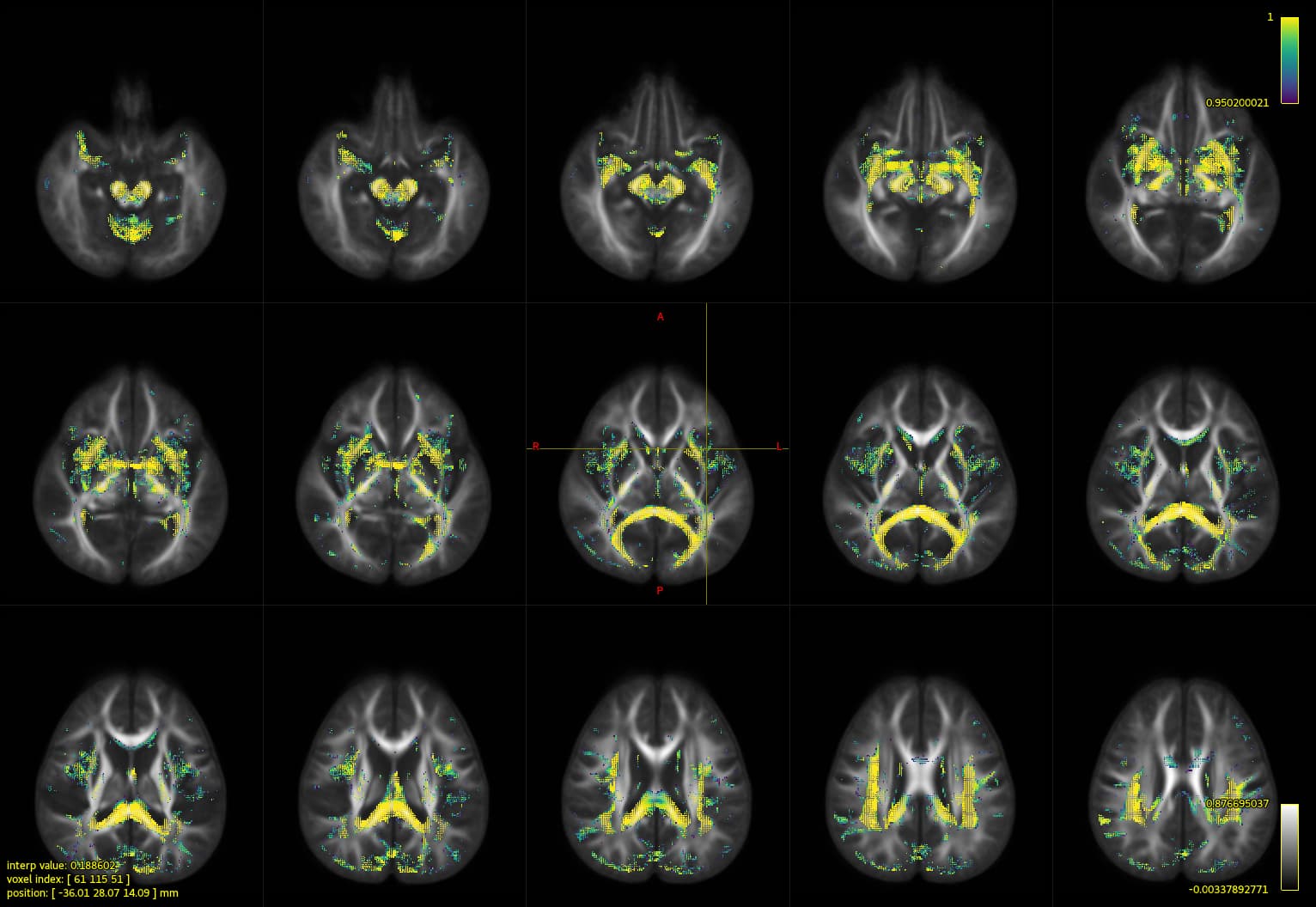
Results with Z-trans fdc comparison
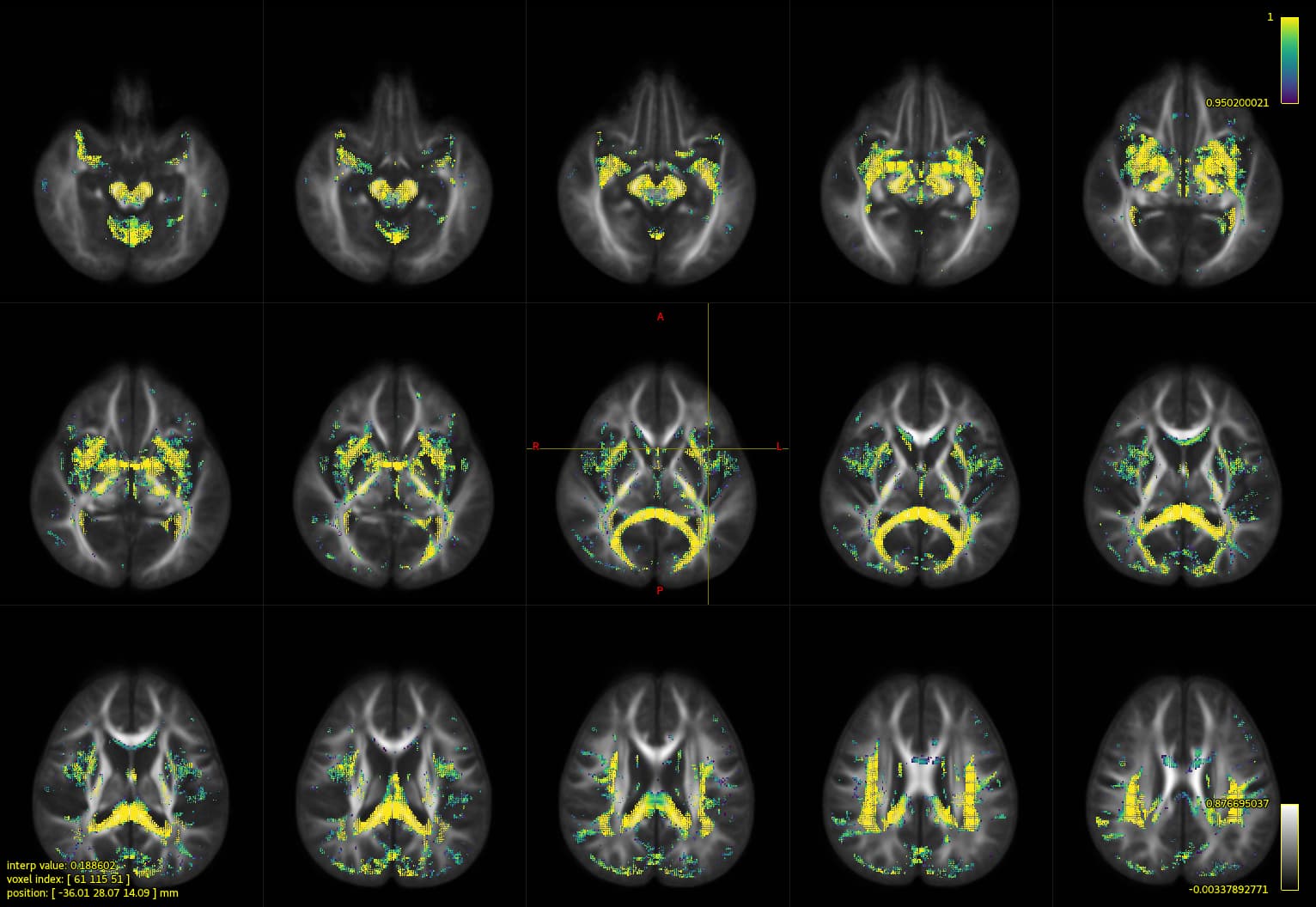
ray
… there are still many small fixel clusters exist in results. I wonder if there are some additionally processes to improve the results.
Ultimately the statistical inference in CFE is applied individually to each fixel, so even if a single isolated fixel shows up, it is statistically significant at your nominated alpha level (e.g. 0.05) with FWE correction. I’m curious what it is about different datasets that may make such observations more or less prevalent—there seems to be a bit more in your data than is typical—but this requires exceptionally careful and detailed interrogation of the data.
One concept I started playing with, but have not yet exhausted technically, is to apply a post hoc cluster size threshold to the binary fixel significance map, to ignore fixel clusters of small size (which has precedent in other domains of statistical inference). Just as maskfilter has a connected-component analysis available through the connect filter, fixelfilter also has a connect filter, which builds supra-threshold fixel clusters based on the fixel-fixel connectivity matrix. Feel free to have a tinker; I’m sure I could have a better solution with more time, but maybe it’s at least somewhat useful.
Cheers
Rob
Hi Rob
I’m sorry for the late reply. Deeply appreciate for your help. After several times attempts, I finally get the result I want. I’ve learned too much from here, thanks!
ray