Really excited to try running an FBA. In addition to running an FBA on the entire fixel grid, I want to try running an FBA within a given tract. I primarily use TractSeg for tract segmentation/reconstruction. I see three potential ways to get a tract mask to use for FBA.
Run TractSeg in native space → warp masks to template → find intersection of all subjects’ tract masks
Warp FODs to template → run TractSeg in template space → find intersection of all subjects’ tract masks
Run TractSeg on group composite FOD Template
I think I can safely rule out 3, since my cohort has 900 subjects and my template would be built off of 30-40 subjects.
From what I can tell, a recent preprint did method 2 (run TractSeg on subject-wise FODs/peaks in template space). Do you think this is the right way to go about this?
The TractSeg software (Wasserthal et al.,2018; GitHub - MIC-DKFZ/TractSeg: Automatic White Matter Bundle Segmentation) allows for automated accurate tract segmentation (e.g., when applied to the FBA study-specific FOD template), the output of which can be used, e.g., to label FBA results or to extract tract-averaged metrics
Does this imply that option 3 (run TractSeg on the group-composite FOD image) is recommended? Is this true even if only a subset of subjects are used to make the template?
Well, I would say it depends a little bit on how you are using TractSeg. Output can be binary voxel mask or tractography file. For the first, I would say, you can go with a number 1. However, if you get tracography files as an output of TractSeg (better in my opinion), you can convert this to fixels and create fixel mask (better then just a plane voxel mask) and use it for a way better tract analysis, since you can use only a certain fixels not a whole voxel as with a voxel mask. In this case, since it is important to have uniformity to compare what is comparable, I would run TractSeg on a template and ten mask FODs warped to the template, to use tracts that are “build” from same fixels for all subjects.
But take it only as my personal opinion. Good luck
Thanks for the response! I agree about the tractography vs. voxel mask point; I initially thought in terms of voxels because in the FBA pipeline that’s how the initial brain masks are calculated (voxel-wise intersection of all subject brain masks), but realize a tract fixel mask would be more specific. In this case, yes I agree these can be produced in template space using the reoriented FODs. The point I am still unsure of is the last sentence, where (at least in my case with a huge cohort) the masks wouldn’t come from all subjects. Maybe I am overthinking this step and placing too much weight on it; curious to hear what anyone else thinks!
Following up here, but I can see two potential ways to proceed, and I don’t know if one is better (or valid/invalid). This is based on the FBA pipeline tutorial.
Changing step 12 and generating the white matter fixel mask from the template-space track segmentation instead of the whole brain mask. This would be using the voxel-wise TractSeg tract segmentations. This fixel mask would be propagated through the rest of the tutorial.
Change step 21 and generate the fixel-fixel connectivity matrix using the tract-specific .trk file instead of the whole brain tractogram. This matrix would be propogated through the rest of the tutorial.
I see three potential ways to get a tract mask to use for FBA.
Three ways utilising TractSeg. There’s always the track editing approach: select (whether manual or automated) a subset of streamlines corresponding to the bundle of interest, and select the set of fixels traversed by those streamlines. This is still moderately common given it only needs to be done once for the whole study.
Does this imply that option 3 (run TractSeg on the group-composite FOD image) is recommended?
The quoted text only says that that approach can be used. If one of these options were to be preferable in terms of data quality, I would hypothesize option 1 based on the fact that TractSeg was trained on individual subject data; though it does complicate the process of accumulating data across subjects. In the absence of evidence of any detriment in doing so, I’d probably choose option 3 simply because it’s so much simpler computationally. But I wouldn’t put “recommended” into the authors’ mouths.
Is this true even if only a subset of subjects are used to make the template?
As long as the template is adequately representative. If there were some consequence in using a subset of subjects only for forming the template in terms of applicability / performance of TractSeg, there would probably be consequences of such beyond TractSeg.
The point I am still unsure of is the last sentence, where (at least in my case with a huge cohort) the masks wouldn’t come from all subjects.
Well, if you use option 3, the tract masks aren’t even “coming from a subset of subjects”: the template came from a subset of subjects, and tract masks are calculated on the resulting template agnostic to the subjects from which that template was generated. The fixel correspondence step in the FBA pipeline deals with establishing a common set of fixels across all subjects; all TractSeg would be doing is storing a 1 in some fixels and a 0 in others.
Changing step 12 …
Change step 21 …
While you can do that, it makes everything downstream of such specific to your tract of interest. If you were to then want to look at some other tract in the same data, you’d have a lot of recalculation to do. Generally in this scenario I’d advise instead proceeding largely as per the whole-brain analysis pipeline, and changing just the final analysis. For instance, you could even still compute the fixel-fixel connectivity matrix and perform data smoothing using all fixels, and only at the very final fixelcfestats step do you constrain statistical inference to only your tract of interest.
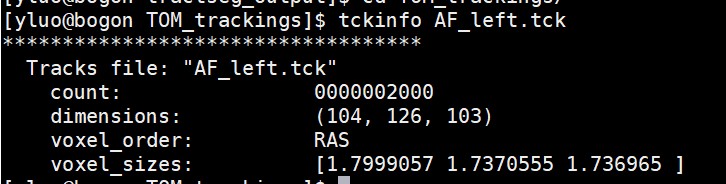
hi,smeisler. I wonder how to run TractSeg in template space.I would be very grateful if you could teach me. As far as I am concerned, the file type of the the template space is the mif, however, the input of the TractSeg is the nii.gz
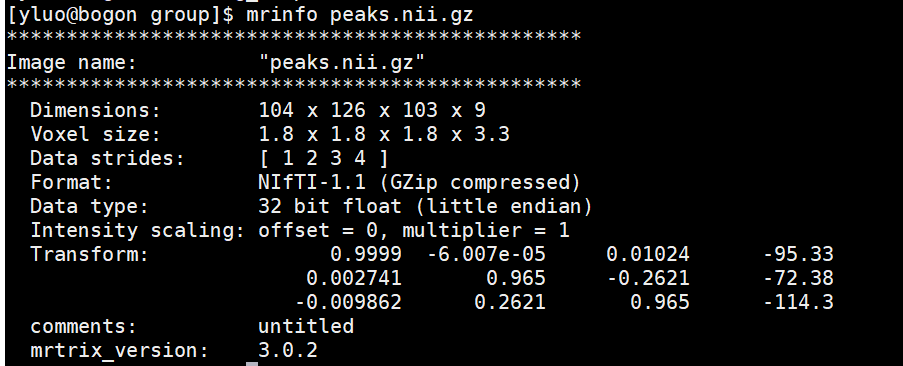
Thank you very much. I run these commands. However,the voxel size of the peaks file is 1.81.81.8, the final track file is 1.791.731.73. Could you teach me how to solve it.
TractSeg -i peaks.nii.gz --output_type tract_segmentation
TractSeg -i peaks.nii.gz --output_type endings_segmentation
TractSeg -i peaks.nii.gz --output_type TOM
Tracking -i peaks.nii.gz --tracking_format tck
The track file does not intrinsically possess a voxel size; streamlines are expressed as vertex locations in scanner space independently of any particular voxel grid. The entry in your first screenshot is merely sidecar information that has been written as text into the header of the queried track file. Where this information has come from is something specific to TractSeg, so I can’t provide any feedback personally.