I am generating subject-level structural connectomes based on the recently published Nature Protocol (Structural connectome construction using constrained spherical deconvolution in multi-shell diffusion-weighted magnetic resonance imaging | Nature Protocols). I have followed the protocol exactly and applied it to our data. Our acquisition parameters meet all HARDI requirements, and match those mentioned in the protocol quite closely.
When I follow the QC protocol in the supplement, everything looks as it should, except for the streamline endpoints, which appear as shown below.
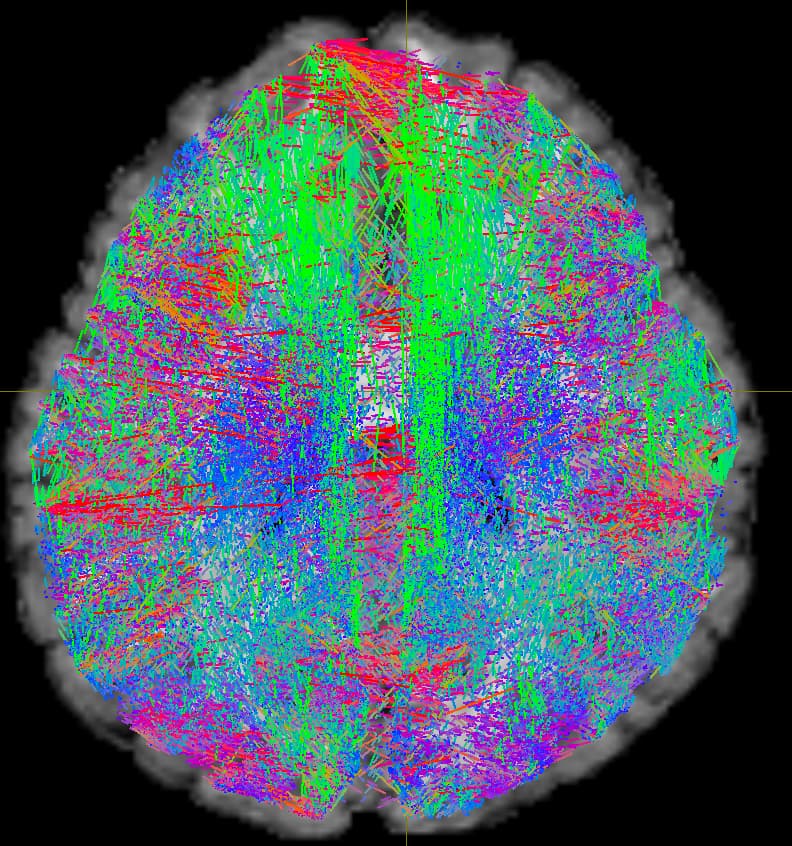
I am not sure what to make of this, why this is happening, and whether it has any implications on downstream connectome generation?
My main questions, however, concern (1) the resulting fiber bundle capacity (FBC) edge values produced, and (2) whether or not scaling by SIFT2’s mu is automatically done.
(1) When I produce the connectome .csv file (84x84 matrix based on FreeSurfer DK atlas) with the SIFT2 weights as input, I am getting FBC values ranging from near zero to 20,000 for some subjects and near zero to 3000 for others. I am struggling to find normative raw FBC values for this pipeline. Are these values plausible, or does if reflect an error somewhere in my pipeline? Since the weights are so large, my calculated global efficiency values are upwards of 6500, which I’ve been told by a mentor is not biologically plausible.
(2) I have read this paper - https://www.humanbrainmapping.org/files/Aperture%20Neuro/Accepted%20Works%20PDF/10_1015_Smith_Quantitative_streamlines_tractography.pdf - and agree with its conclusions. Furthermore, since I am interested in intersubject connectome comparison, I would like to scale each subject’s connectome by mu. Is this automatically done by the tcksift2 and/or tck2connectome commands? I’m assuming not, as the tck2connectome command (within the Nature Protocol and exact command I am currently using) only takes as input the weights (seemingly non-scaled) from tcksift2 output. If this is not automatically done, how would I apply this in practice? Do I simply multiply all resulting FBC values in the .csv file by mu, or is it more complicated than that? I am having trouble finding practical documentation/help on this issue.
Your guidance is much appreciated, and I thank the MRtrix team for such great tools and theoretical insight.