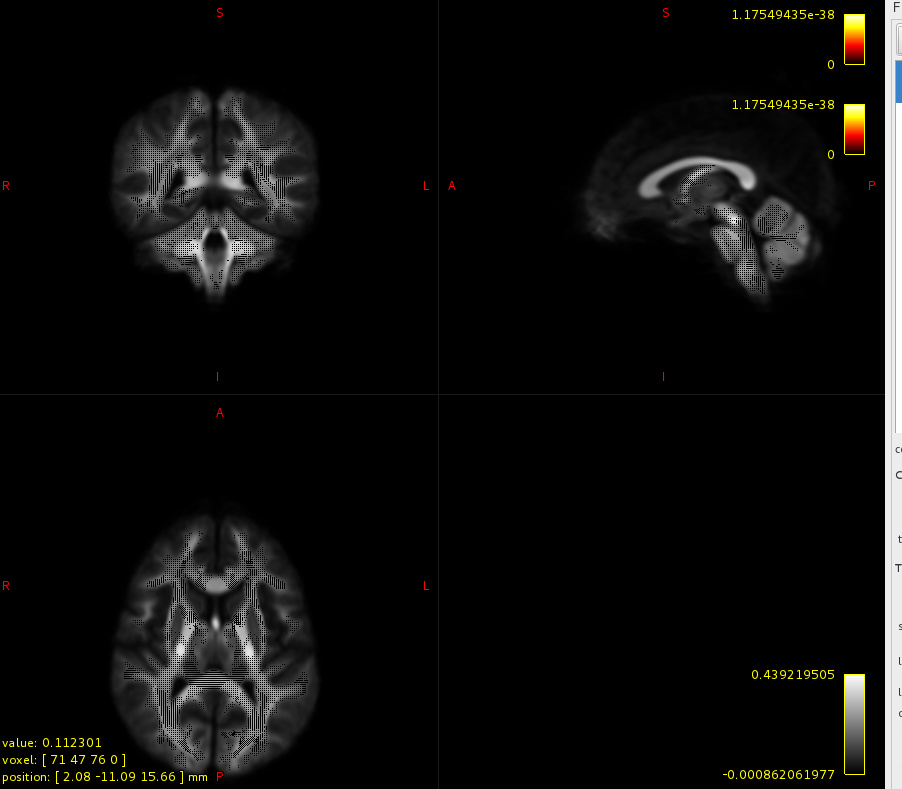
I am running fixelcfestats command with sex, age, motion, whole brain volume and IQ. The result gives me a incredibly high p-value that cannot be true (1.17549435e-38). Once I run it without whole brain volume, it gives a reasonable p-value, so it seems the problem lies somehow with the brain volume values. Both FWE-corrected and uncorrected p-values are high. Do you see anything which should be adjusted?
The result gives me a incredibly high p-value that cannot be true (1.17549435e-38).
Describing a couple of confounds here just in case:
1e-38 is in fact a very small number: it’s a decimal point followed by 37 zeroes. Moreover, the image likely doesn’t actually contain this value; what’s more likely happening is that the image consists entirely of zeroes, but mrview is setting the upper limit of the colour bar to the smallest number it can represent that is greater than zero (the lower limit of the colour bar), in order to avoid dividing by zero during various calculations. This could be confirmed by running mrstats on the fixel data file, and checking the minimum and maximum values.
The “p-value” images provided by statistical inference commands in MRtrix3 in fact provide values as (1.0-p). So when the value stored in image fwe_pvalue.mif is ~ 0.0, this in fact represents p ~ 1.0, i.e. no effect.
So your statement that “the p-values are high” is strictly true; just making sure it wasn’t due to two errors cancelling one another out
If this is the case, the data you need to be looking at more closely are the contents of image cfe.mif and file perm_dist.txt, to see if the enhanced t-statistic values in the default permutation are in fact much smaller than those observed in the null distribution.
Based on recent experience, I would also suggest importing your design matrix into Matlab or Octave and calculating its “condition number”. If this is >> 1.0 it can lead to all sorts of issues…
What I now tried to do is normalize the age column by subtracting by the mean and then dividing by the standard deviation. Is this the proper way to deal with this issue?
Did i do something else wrong here? Is it necessary to normalize covariates and what is the best way to do this?
Do you mind elaborating a bit more on the statistics and rationale behind why one must see ’ if the enhanced t-statistic values in the default permutation are in fact much smaller than those observed in the null distribution’, and what one should do if this is not the case?
Hello @rsmith ,
I am wondering if I transform fwe_1mpvalue.mif into voxel space using fixel2voxel command. How are the p-values stored there? In fixel plot view, the lower threshold is 0.95. What shall be the lower threshold in voxel space.
Many Thanks,
Suren