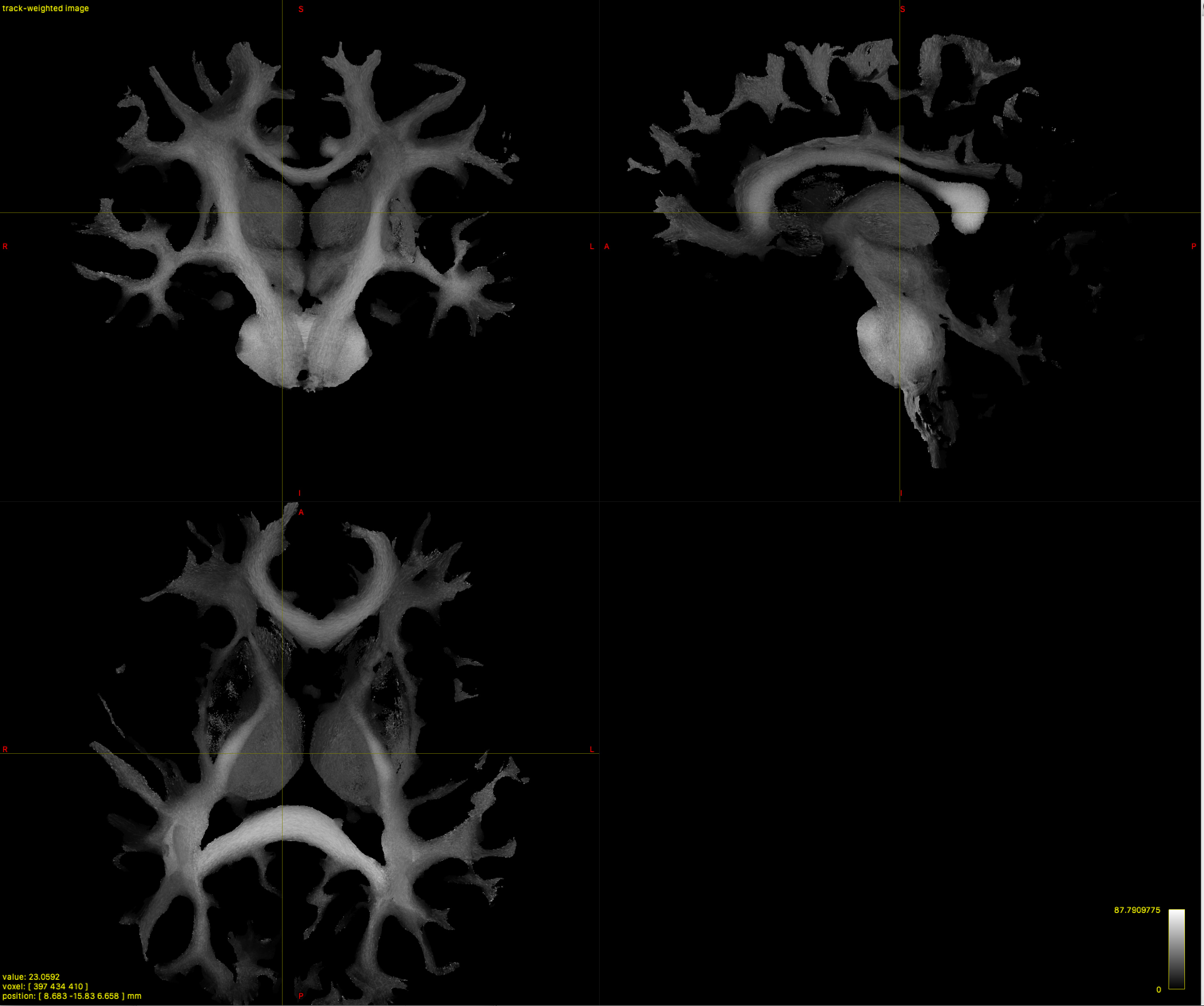
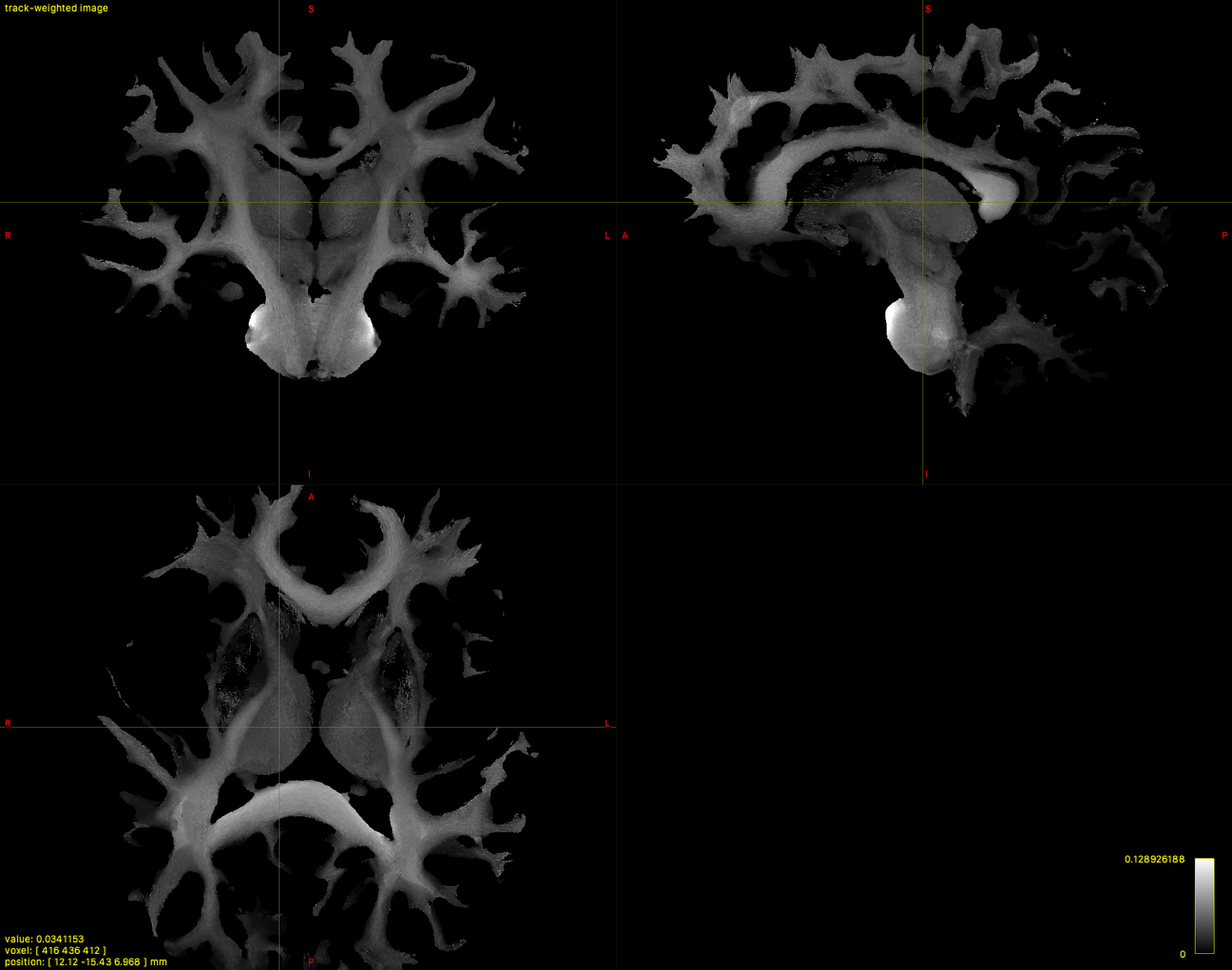
Going back to my original FA.mif for this subject, I found that those values are not between 0 and 1:
mrstats FA.mif
volume mean median stdev min max count
[ 0 ] 0.0491714 0 0.128899 0 1.22474 3571506
When I compute FA for this subject with either DTIFIT or RESTORE, the values are textbook-like: from 0 to 1. I could use other packages to get around this issue, but I’d prefer to stay within MRTrix for consistency, and also I’d love to understand what’s going on. That said, images look great, so I’m not quite sure what I’m doing wrong. The data is HARDI, 63 directions (350, 800, and 2000), 6 B0, plus 6 B0 in opposite direction for TOPUP, was preprocessed including denoise, TOPUP, Gibbs ringing and eddy correction (with repol), 1.8 isotropic upsampled to 1.3 (I’ve ran FBA on this with some exciting results, hence the upsampling size I did according to your recommendations from the FBA documentation). I used dwi2tensor as in the default setting, with 2 iterative reweightings. Masking for 1.3 images was done by dwi2mask with subsequent manual correction. Not sure what other details I can provide, please let me know if I can provide more information / pictures / stats. I’m puzzled, please advise!
In case needed, here is the command I used to generate TW files:
tckmap 10M.tck -tck_weights_in sift2.txt TW-FA.mif -vox 0.18 -contrast scalar_map -image FA.mif -stat_vox mean -stat_tck sum
The issue of FA values greater than 1 is basically due to noise, and the fact that the tensor fitting process in MRtrix3 is unconstrained – as outlined in this post and this post. Using multi-shell data in the tensor fit can also contribute here, since the DW signal does not decay mono-exponential (which the tensor model implicitly assumes).
Also, check which voxels have FA>1, you might find they’re predominantly non-brain voxels…?
This is taking the sum of the FA values sampled along each individual streamline as the quantitative values ascribed to them. So a streamline 100mm long with a step size of 1mm where FA~0.5 along its length will get a value of ~50. I’m guessing you want -stat_tck mean?
… I found that those values are not between 0 and 1 … When I compute FA for this subject with either DTIFIT or RESTORE, the values are textbook-like: from 0 to 1.
While dwi2tensor does not have this constraint, there are other benefits to the algorithm used in this command, which are described in the manuscript cited within the “References” section of the command’s help page.
Thank you so much, Donald! And thanks for linking the post! Indeed, my masks are overinclusive, and eroding the masks as well as masking out the CSF (with the help of fISO map from NODDI processing) them does a great job eliminating “weird” FA values.
Yes, predominantly non-brain, but also some CC voxels with FA at 1.2, which was bothering me. With more elaborate masking, FA’s max is .99998 now
Thanks, Rob! Apparently, I am not understanding something here. I was referring to Willats et al (2014), and thought that since I gave it the option of -stat_vox mean, it will give me the mean voxel value for FA after accounting for all the streamlines going through that voxel. It seems a little strange to me that a value of a voxel would be determined by one of the streamlines passing through that voxel, furthermore, accumulating information about the whole length of that streamline. Could you please explain a bit more?
Veraart paper is great; the first thing I did before running dwi2tensor is reading that paper. However, I think I need to get back to it - I didn’t realize the presence of noise and non-brain voxels can so significantly impact the values of the brain voxels, especially in such a place as the body of CC - where I found some voxels with FA of 1.2.
Thank you so much for your help! You guys are phenomenal, and your support is exceptional! This is gold when a neuroscientist starts to explore neuroimaging.
I’ll try; I wasn’t entirely happy with the language used in the description of the method in the 2013 TWI manuscript, so I’ll explain how I personally think about it.
With the exception of the case of Gaussian smoothing along the track (which has been nothing but a nightmare to support and continues to be so), you can think of TWI generation as consisting of two sequential calculations:
For each streamline, compute a value at each streamline vertex. In your case you’re providing an FA image as the scalar map, so each streamline vertex has a value of FA underlying it. You then need to calculate some statistic from these values, in order to produce a single scalar value for that streamline. I refer to this as the “track-wise statistic”.
For each voxel, there exists a set of streamlines that intersect that voxel. Each of those streamlines has a scalar value associated with it, as calculated from step 1. Therefore, to produce a single scalar value for that voxel, you need to compute some statistic from those per-streamline values. I refer to this as the “voxel-wise statistic”.
So in the case of “TW FA”, I would technically refer to this as the “mean mean FA”: It’s the mean FA value along each streamline, and then for each voxel it’s the mean value across all traversing streamlines. But both of these steps need to be explicit, since there are myriad other TWI use cases where one or both of these steps may use a different statistic.
Slightly on-topic, since I happened to have the code in front of me mere seconds before opening this post: In a future software update this mechanism is made even more explicit, by splitting steps 1 and 2 across separate commands. I’m hoping that will make things more clear for many people who have experienced similar misunderstandings.