I have general questions, I’m looking for advises regarding the following strategies. I’m not working with ODF so I’m wondering how the general strategies depicted in the forum can be applied on my data. I wish to disclaim that I’m a beginner in such processing.
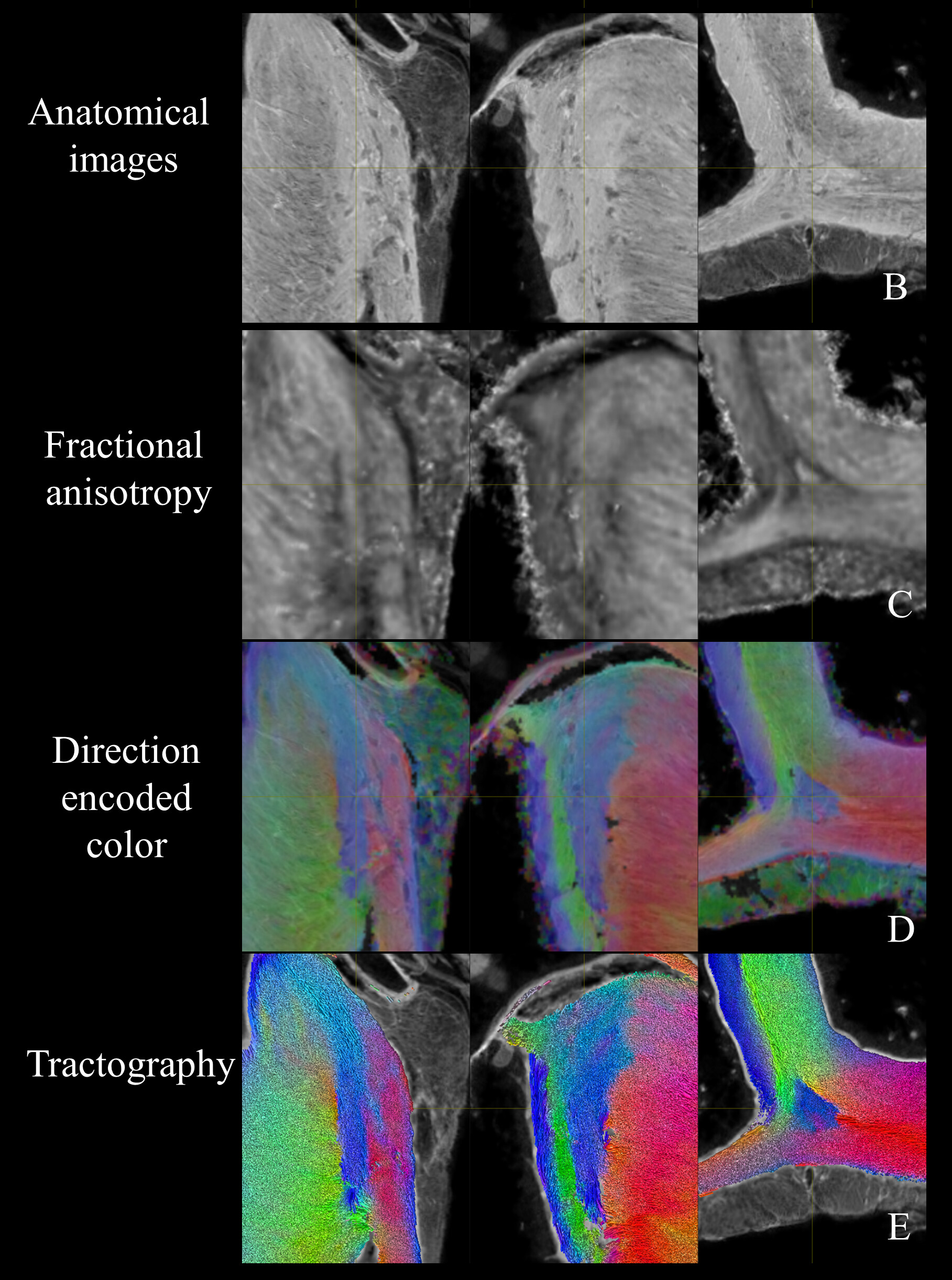
Please find below some figures, I have 3 objectives :
demonstrate that the some structures (for instance the singularity in blue with a triangular shape) has a different fiber orientation
create a parcellation map based on fiber orientation
extract relevant feature like the size and volume of this structure
Strategies 1 (done except the parcellation):
estimate tensor in subject spaces using dwi2tensor (using MRtrix)
warp tensor in template spaces (using ANTs)
average all tensors in template spaces to get a unique average tensor (using ANTs)
extract eigenvector of the averaged tensor (using MRtrix)
using FACT to compute the streamline (using MRtrix)
display the streamlines and create a parcellation atlas in template space
Strategies 2 (done except the parcellation):
compute tractography in subject spaces using Tensor_Det or Tensor_Prob using DWI data (using MRtrix)
display the streamlines and create a parcellisation atlas in template space
Please find below some questions:
Which strategy would you recommand ? Maybe none of them ? For strategies 1, my concern is that tckgen FACT differs a lot from Tensor_Det or Tensor_Prob.
In strategy 2, I’m wondering what can I do to average my streamlines or extract relevant features. According to the following post : *.tck file add and average, there is no streamline averaging in MRtrix and tcksift or tcksift2 cannot be used in non-ODF data , could you confirm ?
Is it relevant to use tckmap on non-ODF data. If relevant (I’m not sure), which metrics would you advise ? or could you indicate references/articles that used tckmap with non-ODF data ?
Does MRtrix offer the possibility to create a parcellisation map based on eigen-vector or tractography. I’m really struggling with this step. I tried to combine tckgen with -direction 0,0,1 option followed by tckmap but it was not so easy to binarize the output of tckmap. Is there any command /method to create parcellisation map base on DTI.
Your intended analysis is very much non-standard, so there’s a wide scope of possibilities for what could potentially be done and to what extent things could be made automated / objective rather than manual / subjective. Before getting to your questions, this sticks out to me:
create a parcellation map based on fiber orientation
Is your intention to implement / utilise some form of automated parcellation algorithm for deriving such in a data-driven way? The answer to that question quite drastically changes the scope of the project. It bears some limited resemblance to some work I did during my PhD, which we could discuss if you plan to go that far; but if you’re purely generating the requisite data in order to perform a manual segmentation upon such, then nevermind.
Strategy 1:
A potential disadvantage with this sort of approach—which I know to have been a concern with some rather influential manuscripts in the past—is that despite the inter-subject variance in the tensor estimates across subjects once warped to template space, a single group average tensor is produced per voxel, and then a single discrete fibre orientation is extracted per voxel, and then all streamlines traversing that voxel select only that exact orientation to follow. So the tractography outcomes will look exceptionally “clean” and “sharp”, but this runs the risk of being quite misleading. Particularly anywhere where the tensor model is inadequate, and you could even have tensors from different subjects pointing in very different directions, tracking on just the principal eigenvector of just the group average tensor will completely mask that ambiguity. That’s not to say it can’t / shouldn’t be done, it’s just worth bearing in mind when interpreting such streamlines data that its high precision may completely mislead you regarding its accuracy. For instance, you could end up with a very sharp and well-defined structure in template space that is not actually a very good representation of anything that appears in any individual subject.
Strategies 2:
This will “work”; but you’ll undoubtedly find that the definition of structures of interest is not as sharp. Indeed it might actually look quite unusual having deterministic streamlines from subject spaces all warped to template space, where there will be “batches” of deterministic streamlines following one another perfectly yet many such batches with different orientations…
Strategies 3:
Is there any strong reason for:
I’m not working with ODF so I’m wondering how the general strategies depicted in the forum can be applied on my data.
? You could warp individual subject FOD data into a common FOD template, and then perform tractography on that just as we do for CFE / FBA.
While FACT and Tensor_* operate on different data, the biggest observable difference between FACT and Tensor_Det is the absence of fibre orientation interpolation in the former. Streamlines look really jagged and ugly as a result. FACT is mostly there implemented as a demonstration of how tracking algorithms implemented in that fashion operate; its existence should not be interpreted as advocacy. Not that we exactly advocate for the use of the Tensor_* algorithms either…
As with the linked post, there is some ambiguity here about what is meant by “averaging” streamlines. Since for Strategy 2 you mentioned concatenating tractograms using tckedit, you must be intending to refer to something else here, but it’s not clear exactly what that is.
As for the applicability of SIFT(2), there are two points to be made here:
The command interfaces currently expect an FOD image as input, as they perform the same FOD segmentation as is used in fod2fixel, but retain additional information about the orientation dispersion of fixels as this improves the process of streamline attribution to fixels. I’ve always wanted both to have tcksift(2) support the use of a fixel directory as input, and to export data for that superior streamline-fixel assignment to fixel directories for later use, it’s just one more can being kicked down the road; maybe that’s unnecessary detail, but my point is that either getting data into a format that can be read by these tools, or instructing those tools how to receive inputs of a different format, is only a technical implementation issue.
Fundamentally, the logic of these algorithms requires, for every fixel (or even just every voxel theoretically), an estimate of fibre density. So they’re technically not strictly tied to spherical deconvolution ODFs (even though it’s in the name), an alternative diffusion model that provides (a) fibre density estimate(s) could theoretically be used. But the tensor model provides no such meaasure.
tckmap doesn’t care how the streamlines you provide to it were generated. It’s entirely “relevant” in so far as that it will provide you with an alternative way in which to visualise / quantify your data. Whether or not those data, i.e. the streamlines, are of sufficient “relevance” is a question deferred to the wider experiment, not of that specific processing step.
If by “metrics” you are referring to the various options available within the TWI framework, I would refer to your end goal, which is performing some form of parcellation in template space. If you can generate an image that contains contrast that can be used to drive that parcellation (whether manual or automated), I’d consider that “relevant”.
This really links back to my very first question. There’s a number of layers of complexity embedded within this question: what information are you encoding in each voxel, how do you define “similarity” or “dissimilarity” between adjacent voxels, what kind of algorithm do you apply to utilise this information to cluster similar voxels or to determine boundaries between parcels. Back at the start of my PhD I looked into some methods in this kind of domain as it beared some resemblance to my own project; the first one that comes to mind is this method from Maxime Descoteaux; you could probably find similar methods by tracking the citations in either direction. So there’s no existing MRtrix3 command that will do anything like this, and you’ll have to think about the full domain of possible ways to pull something like this off. I’ll link to my 2011 ISMRM abstract: it’s definitely not the same as what you are wanting to do here, in that it aims to segment WM bundles rather than WM volumes, but there might be some ideas from there that you could borrow from if you want to pursue a tailored solution for your task.
First, I would like to thank you a lot for this really helpful answer. It was really pleasant to read and help me a lot and confirm many observations. Please find below the answer to the discussion.
Yes, creating a parcellation map based on fiber orientation is my ultimate objective. I would prefer to implement an automated parcellation algorithm rather than do manual segmentation. Nevertheless, I have no idea how to do it. In case you know any mix manual/auto segmentation ? I tried to segment manually an specific area but it quickly became highly difficult and subjective , in particular at the border zone or when the orientation of the fibers has a 45° angulation in comparison to the reference frame I’m looking at. This is really theoretical, but at time equal (implementation versus segmentation), I would prefer an objective poor automated method than a subjective manual method.
Strategy 1:
Your comments confirm my thought, I fully agree with the “you could even have tensors from different subjects pointing in very different directions, tracking on just the principal eigenvector of just the group average tensor will completely mask that ambiguity”. On the other hand, as I wish to make a parcellation, having a very sharp and well-defined structure is currently fine for me.
Strategy 2:
OK
Strategy 3: the acquisition with 6 directions 1 b0 value (the minimum) spent about 24 h (I don’t remember the exact timing). Therefore I’m using a simple tensor description. I will have in the next few months new data with 45 directions and 1 b0 value but I need to first use my 6 direction datasets. So I guess I cannot use the ODF description.
About FACT and Tensor. OK
About averaging. Actually I’m concatenating tractograms using tckedit. I’m not doing averaging. I’m looking for a feature that could simplify the fiber distribution from strategies #2. It could be helpful just for making some figures.
2.1) If I understand well, it is not impossible but need to do some coding
2.2) OK
About tckmap. Tckmap could be relevant with the tensor description. Maybe I need to push my investigation using tckmap to drive the parcellation therefore. It wasn’t straightforward at first glance.
To be honest I haven’t yet found/implemented anything even less close to what you mentioned. The reference is really interesting and this is exactly the kind of tool I’m looking for…I have naively started with some sobel filter made on each vector component to get an idea of the compartiment, but this only works if the structure is aligned with the x,y,z frame. In general, the structures I wish to segment are massive so I’m quite convinced that a simple clustering algorithm should do the job if I can incorporate just the fiber orientation to guide the clustering. I will dig in the citation of the abstract and the paper (I have to admit that it looks a bit intense at first glance ). I let you know
I would prefer to implement an automated parcellation algorithm rather than do manual segmentation. Nevertheless, I have no idea how to do it. In case you know any mix manual/auto segmentation ?
I suspect from your phrasing that this particular component may be a much larger and more complex undertaking than currently perceived. The nature of the data on which you are operating is quite different to that for which existing clustering algorithms are designed. If the conception and development of a tailored clustering solution for > 3D image data is not already at the forefront of your goals, but is simply a “yeah, that’d be nice”, I’d probably suggest striking it off the list of possibilities that are within scope.
the acquisition with 6 directions 1 b0 value (the minimum) spent about 24 h (I don’t remember the exact timing). Therefore I’m using a simple tensor description.
Teeechnically you could do an FOD fit with lmax=2…
I’m looking for a feature that could simplify the fiber distribution from strategies #2.
It’s not clear what is intended here with “simplify”.
About tckmap. Tckmap could be relevant with the tensor description. Maybe I need to push my investigation using tckmap to drive the parcellation therefore. It wasn’t straightforward at first glance.
I’m wondering if my answer here was too philosophical regarding use of the word “relevant” when it was actually a slightly erroneous choice of word in the first place, and that’s just confused the situation further… Do you simply want to know if streamlines generated using non-ODF data are “applicable” to tckmap? If so, yes. But there might nevertheless still be some confusion about what the input to & output from this command is, and how that relates to the diffusion tensor model (read: not at all).
To be honest I haven’t yet found/implemented anything even less close to what you mentioned. …
Basic convolution filters are only applicable if the value in each voxel on which you are operating is a scalar (e.g. track density). The visual observation you’re making that you’re thinking could drive the registration (e.g. change in colours) wont be nearly as present in such data. While it might be possible to do something using a directionally-encoded colour image to incorporate some orientation information, this isn’t ideal as the mapping of XYZ direction to RGB colour includes a loss of information (as absolute values must be taken). The necessity of incorporating fibre orientation information in order to exploit such is why I provided that abstract link (there’s more detail in my thesis if you really want to put yourself to sleep); indeed in the most general case you have to consider not just a single orientation per voxel, but the distribution of streamlines orientations in each voxel. Then you have to consider whether you want to not only utilise orientation information as contrast in an otherwise orientation-agnostic clustering algorithm, or whether the clustering algorithm itself should be designed around the utilisation of this orientation information; again, hence the abstract link. So there’s a rather large rabbit hole to be lost in here if you’re not careful.